In my last blog entry about Direct I/O, I covered the topic of what Direct I/O can mean beyond normal Oracle database files. A reader followed up with a comment based on his experience with Direct I/O via Solaris –forcedirectio mount option:
I’ve noticed that on Solaris filesystems with forcedirectio , a “compress” becomes quite significantly slower. I had a database where I was doing disk-based backups and if I did “cp” and “compress” scripting to a forcedirectio filesystem the database backup would be about twice as long as one on a normally mounted filesystem.
I’m surprised it was only twice as slow. He was not alone in pointing this out. A fellow OakTable Network member who has customers using PolyServe had this to say in a side-channel email discussion:
Whilst I agree with you completely, I can’t help but notice that you ‘forgot’ to mention that all the tools in fileutils use 512-byte I/Os and that the response time to write a file to a dboptimised filesystem is very bad indeed…
I do recall at one point cp(1) used 512byte I/Os by default but that was some time ago and it has changed. I’m not going to name the individual that made this comment because if he wanted to let folks know who he is, he would have made the comment on the blog. However, I have to respectfully disagree with this comment. It is too broad and a little out of date. Oh, and fileutils have been rolled up into coreutils actually. What tools are those? Wikipedia has a good list.
When it comes to the tools that are used to manipulate unstructured data, I think the ones that matter the most are cp, dd, cat, sort, sum, md5sum, split, uniq and tee. Then, from other packages, there are tar and gzip. There are others, but these seem to be the heavy hitters.
Small Bites
As I pointed out in my last blog entry about DIO, the man page for open(2) on Enterprise Linux distributions quotes Linus Torvalds as saying:
The thing that has always disturbed me about O_DIRECT is that the whole interface is just stupid, and was probably designed by a deranged monkey on some serious mind-controlling substances
I beg to differ. I think he should have given that title to anyone that thinks a program like cp(1) needs to operate with little itsy-bitsy-teenie-weenie I/Os. The following is the current state of affairs (although not exhaustive) as per measurements I just took with strace on RHEL4:
- tar: 10KB default, override with –blocking-factor
- gzip: 32KB in/16KB out
- cat, md5sum, split, uniq, cp: 4KB
So as you can see these tools vary, but the majority do operate with insidiously ridiculous small I/O sizes. And 10KB as the default for tar? Huh? What a weird value to pick out of the air. At least you can override that by supplying an I/O size using the –blocking-factor option. But still, 10KB? Almost seems like the work of “deranged monkeys.” But is all lost? No.
Open Source
See, I just don’t get it. Supposedly Open Source is so cool because you can read and modify source code to make your life easier and yet people are reluctant to actually do that. As far as that list of coreutils goes, only cp(1) causes a headache on a direct I/O mounted filesystem because you can’t pipeline it. Can you imagine the intrusive changes one would have to make to cp(1) to stop doing these ridiculous 4KB operations? I can, and have. The following is what I do to the coreutils cp(1):
copy.c:copy_reg()
/* buf_size = ST_BLKSIZE (sb);*/
buf_size = 8388608 ;
Eek! Oh the horror. Imagine the testing! Heaven’s sake! But, Kevin, how can you copy a small file with such large I/O requests? The following is a screen shot of two copy operations on a direct I/O mounted filesystem. I copy once with my cp command that will use a 8MB buffer and then again with the shipping cp(1) which uses a 4KB buffer.
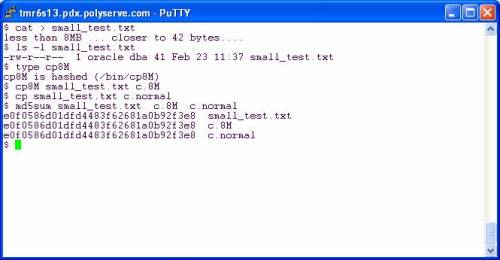
Folks, in both cases the file is smaller than the buffer size. The custom cp8M will use an 8MB buffer but can safely (and quickly) copy a 41 byte file the same way the shipping cp(1) does with a 4KB buffer. The file is smaller than the buffer in both cases—no big deal.
So then you have to go through and make custom file tools right? No, you don’t. Let’s look at some other tools.
Living Happily With Direct I/O
…and reaping the benefits of not completely smashing your physical memory with junk that should not be cached. In the following screen shot I copy a redo log to get a working copy. My current working directory is a direct I/O mounted PSFS and I’m on RHEL4 x86_64. After copying I used gzip straight out of the box as they say. I then followed that with a pipeline command of dd(1) reading the infile with 8MB reads and writing to the pipe (stdout) with 8MB writes. The gzip command is reading the pipe with 32KB reads and in both cases is writing the compressed output with 16KB writes.
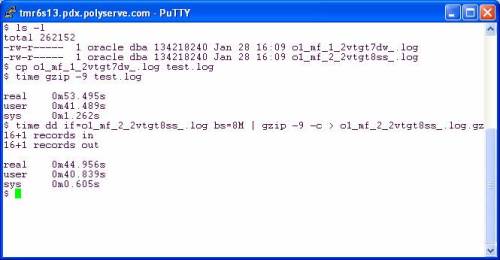
It seems gzip was written by monkeys who were apparently not deranged. The effect of using 32KB input and 16KB output is apparent. There was only a 16% speedup when I slammed 8MB chucks into gzip on the pipeline example. Perhaps the sane monkeys that implemented gzip could talk to the deranged monkeys that implemented all those tools that do 4KB operations.
What if I pipeline so that gzip is reading and writing on pipes but dd is adapted on both sides to do large reads and writes? The following screen shot shows that using dd as the reader and writer does pick up another 5%:

So, all told, there is 20% speedup to be had going from canned gzip to using dd (with 8MB I/O) on the left and right hand of a pipeline command. To make that simpler one could easily write the following scripts:
#!/bin/bash
dd if=$1 bs=8M
and
#!/bin/bash
dd of=$1 bs=8M
Make these scripts executable and use as follows:
$ large_read.sh file1.dbf | gzip –c -9 | large_write.sh file1.dbf.gz
But why go to that trouble? This is open source and we are all so very excited that we can tweak the code. A simple change to any of these tools that operate with 4KB buffers is very easy as I pointed out above. To demonstrate the benefit of that little tiny tweak I did to coreutils cp(1), I offer the following screen shot. Using cp8M offers a 95% speedup over cp(1) by moving 42MB/sec on the direct I/O mounted filesystem:

More About cp8M
Honestly, I think it is a bit absurd that any modern platform would ship a tool like cp(1) that does really small I/Os. If any of you can test cp(1) on, say, AIX, HP-UX or Solaris you might find that it is smart enough to do large I/O requests if is sees the file is large. Then again, since OS page cache also comes with built-in read-ahead, the I/O request size doesn’t really matter since the OS is going to fire off a read-ahead anyway.
Anyway, for what it is worth, here is the README that we give to our customers when we give them cp8M:
$ more README
INTRODUCTION
Files stored on DBOPTIMIZED mounted filesystems do not get accessed with buffered I/O. Therefore, Linux tools that perform small I/O requests will suffer a performance degradation compared to buffered filesystems such as normal mounted PolyServe CFS , Ext3, etc. Operations such as copying a file with cp(1) will be very slow since cp(1) will read and write small amounts of data for every operation.
To alleviate this problem, PolyServe is providing this slightly modified version of the Open Source cp(1) program called cp8M. The seed source for this tool is from the coreutils-5.2.1 package. The modification to the source is limited to changing the I/O size that cp(1) issues from ST_BLOCKSIZE to 8 MB. The following code snippet is from the copy.c source file and depicts the entirety of source changes to cp(1):
copy.c:copy_reg()
/* buf_size = ST_BLKSIZE (sb);*/
buf_size = 8388608 ;
This program is statically linked and has been tested on the following filesystems on RHEL 3.0, SuSE SLES8 and SuSE SLES9:
* Ext3
* Regular mounted PolyServe CFS
* DBOPTIMIZED mounted PSFS
Both large and small files have been tested. The performance improvement to be expected from the tool is best characterized by the following terminal session output where a 1 GB file is copied using /bin/cp and then with cp8M. The source and destination locations were both DBOPTIMIZED.
# ls -l fin01.dbf
-rw-r–r– 1 root root 1073741824 Jul 14 12:37 fin01.dbf
# time /bin/cp fin01.dbf fin01.dbf.bu
real 8m41.054s
user 0m0.304s
sys 0m52.465s
# time /bin/cp8M fin01.dbf fin01.dbf.bu2
real 0m23.947s
user 0m0.003s
sys 0m6.883s









Recent Comments