In my last blog entry about Direct I/O, I covered the topic of what Direct I/O can mean beyond normal Oracle database files. A reader followed up with a comment based on his experience with Direct I/O via Solaris –forcedirectio mount option:
I’ve noticed that on Solaris filesystems with forcedirectio , a “compress” becomes quite significantly slower. I had a database where I was doing disk-based backups and if I did “cp” and “compress” scripting to a forcedirectio filesystem the database backup would be about twice as long as one on a normally mounted filesystem.
I’m surprised it was only twice as slow. He was not alone in pointing this out. A fellow OakTable Network member who has customers using PolyServe had this to say in a side-channel email discussion:
Whilst I agree with you completely, I can’t help but notice that you ‘forgot’ to mention that all the tools in fileutils use 512-byte I/Os and that the response time to write a file to a dboptimised filesystem is very bad indeed…
I do recall at one point cp(1) used 512byte I/Os by default but that was some time ago and it has changed. I’m not going to name the individual that made this comment because if he wanted to let folks know who he is, he would have made the comment on the blog. However, I have to respectfully disagree with this comment. It is too broad and a little out of date. Oh, and fileutils have been rolled up into coreutils actually. What tools are those? Wikipedia has a good list.
When it comes to the tools that are used to manipulate unstructured data, I think the ones that matter the most are cp, dd, cat, sort, sum, md5sum, split, uniq and tee. Then, from other packages, there are tar and gzip. There are others, but these seem to be the heavy hitters.
Small Bites
As I pointed out in my last blog entry about DIO, the man page for open(2) on Enterprise Linux distributions quotes Linus Torvalds as saying:
The thing that has always disturbed me about O_DIRECT is that the whole interface is just stupid, and was probably designed by a deranged monkey on some serious mind-controlling substances
I beg to differ. I think he should have given that title to anyone that thinks a program like cp(1) needs to operate with little itsy-bitsy-teenie-weenie I/Os. The following is the current state of affairs (although not exhaustive) as per measurements I just took with strace on RHEL4:
- tar: 10KB default, override with –blocking-factor
- gzip: 32KB in/16KB out
- cat, md5sum, split, uniq, cp: 4KB
So as you can see these tools vary, but the majority do operate with insidiously ridiculous small I/O sizes. And 10KB as the default for tar? Huh? What a weird value to pick out of the air. At least you can override that by supplying an I/O size using the –blocking-factor option. But still, 10KB? Almost seems like the work of “deranged monkeys.” But is all lost? No.
Open Source
See, I just don’t get it. Supposedly Open Source is so cool because you can read and modify source code to make your life easier and yet people are reluctant to actually do that. As far as that list of coreutils goes, only cp(1) causes a headache on a direct I/O mounted filesystem because you can’t pipeline it. Can you imagine the intrusive changes one would have to make to cp(1) to stop doing these ridiculous 4KB operations? I can, and have. The following is what I do to the coreutils cp(1):
copy.c:copy_reg()
/* buf_size = ST_BLKSIZE (sb);*/
buf_size = 8388608 ;
Eek! Oh the horror. Imagine the testing! Heaven’s sake! But, Kevin, how can you copy a small file with such large I/O requests? The following is a screen shot of two copy operations on a direct I/O mounted filesystem. I copy once with my cp command that will use a 8MB buffer and then again with the shipping cp(1) which uses a 4KB buffer.
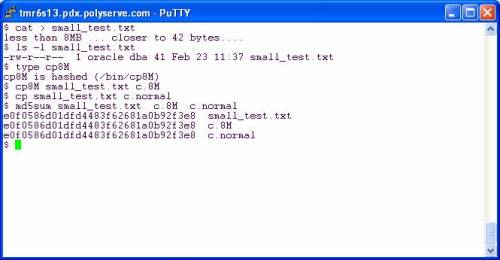
Folks, in both cases the file is smaller than the buffer size. The custom cp8M will use an 8MB buffer but can safely (and quickly) copy a 41 byte file the same way the shipping cp(1) does with a 4KB buffer. The file is smaller than the buffer in both cases—no big deal.
So then you have to go through and make custom file tools right? No, you don’t. Let’s look at some other tools.
Living Happily With Direct I/O
…and reaping the benefits of not completely smashing your physical memory with junk that should not be cached. In the following screen shot I copy a redo log to get a working copy. My current working directory is a direct I/O mounted PSFS and I’m on RHEL4 x86_64. After copying I used gzip straight out of the box as they say. I then followed that with a pipeline command of dd(1) reading the infile with 8MB reads and writing to the pipe (stdout) with 8MB writes. The gzip command is reading the pipe with 32KB reads and in both cases is writing the compressed output with 16KB writes.
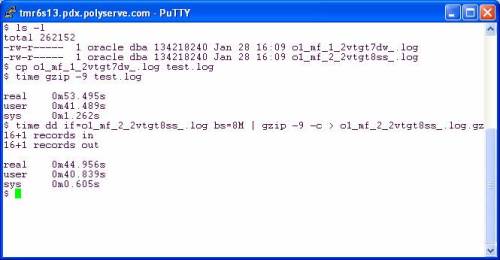
It seems gzip was written by monkeys who were apparently not deranged. The effect of using 32KB input and 16KB output is apparent. There was only a 16% speedup when I slammed 8MB chucks into gzip on the pipeline example. Perhaps the sane monkeys that implemented gzip could talk to the deranged monkeys that implemented all those tools that do 4KB operations.
What if I pipeline so that gzip is reading and writing on pipes but dd is adapted on both sides to do large reads and writes? The following screen shot shows that using dd as the reader and writer does pick up another 5%:

So, all told, there is 20% speedup to be had going from canned gzip to using dd (with 8MB I/O) on the left and right hand of a pipeline command. To make that simpler one could easily write the following scripts:
#!/bin/bash
dd if=$1 bs=8M
and
#!/bin/bash
dd of=$1 bs=8M
Make these scripts executable and use as follows:
$ large_read.sh file1.dbf | gzip –c -9 | large_write.sh file1.dbf.gz
But why go to that trouble? This is open source and we are all so very excited that we can tweak the code. A simple change to any of these tools that operate with 4KB buffers is very easy as I pointed out above. To demonstrate the benefit of that little tiny tweak I did to coreutils cp(1), I offer the following screen shot. Using cp8M offers a 95% speedup over cp(1) by moving 42MB/sec on the direct I/O mounted filesystem:

More About cp8M
Honestly, I think it is a bit absurd that any modern platform would ship a tool like cp(1) that does really small I/Os. If any of you can test cp(1) on, say, AIX, HP-UX or Solaris you might find that it is smart enough to do large I/O requests if is sees the file is large. Then again, since OS page cache also comes with built-in read-ahead, the I/O request size doesn’t really matter since the OS is going to fire off a read-ahead anyway.
Anyway, for what it is worth, here is the README that we give to our customers when we give them cp8M:
$ more README
INTRODUCTION
Files stored on DBOPTIMIZED mounted filesystems do not get accessed with buffered I/O. Therefore, Linux tools that perform small I/O requests will suffer a performance degradation compared to buffered filesystems such as normal mounted PolyServe CFS , Ext3, etc. Operations such as copying a file with cp(1) will be very slow since cp(1) will read and write small amounts of data for every operation.
To alleviate this problem, PolyServe is providing this slightly modified version of the Open Source cp(1) program called cp8M. The seed source for this tool is from the coreutils-5.2.1 package. The modification to the source is limited to changing the I/O size that cp(1) issues from ST_BLOCKSIZE to 8 MB. The following code snippet is from the copy.c source file and depicts the entirety of source changes to cp(1):
copy.c:copy_reg()
/* buf_size = ST_BLKSIZE (sb);*/
buf_size = 8388608 ;
This program is statically linked and has been tested on the following filesystems on RHEL 3.0, SuSE SLES8 and SuSE SLES9:
* Ext3
* Regular mounted PolyServe CFS
* DBOPTIMIZED mounted PSFS
Both large and small files have been tested. The performance improvement to be expected from the tool is best characterized by the following terminal session output where a 1 GB file is copied using /bin/cp and then with cp8M. The source and destination locations were both DBOPTIMIZED.
# ls -l fin01.dbf
-rw-r–r– 1 root root 1073741824 Jul 14 12:37 fin01.dbf
# time /bin/cp fin01.dbf fin01.dbf.bu
real 8m41.054s
user 0m0.304s
sys 0m52.465s
# time /bin/cp8M fin01.dbf fin01.dbf.bu2
real 0m23.947s
user 0m0.003s
sys 0m6.883s



Ah – that’s why the ‘forcedirectio’ mount option should not be preferred over applications using directio(3C) directly where it’s beneficial. At least with UFS on Solaris, Oracle’s filesystemio_options=setall is the better way to engage direct I/O.
The best things in life are only best when not forced.
Cheers,
— Bob
I’ll go with that, Bob. The point, however, was that the common file utilities DON’T use directio(3C) (sol) or O_DIRECT and therefore hound the page cache. The whole point of the thread is to discuss off-loading the cache for those Oracle-related operations that you really shouldn’t want to pollute your cache–such as file compression and so forth.
For what its worth, cp on Solaris 10 uses mmap64 in 8MB chunks to read in data and 8MB write()s to write it out. There are a couple of other things that might be worth mentioning though:
One common utility used for copying that is sometimes overlooked is ftp. Implementations tend to use very small buffer sizes, and worse than that, it tends to have a lot of short reads, followed by short writes of what it has just read.
Most of the utilities you mentioned are single-threaded, so they provide no concurrency themselves, relying instead on the underlying OS and/or hardware to provide it. Direct i/o of course removes the ability of the OS to prefetch data or perform deferred writes. There are however multithreaded utilities. An open-source program I’ve used and been very happy with is http://cdrecord.berlios.de/old/private/star.html
Even beyond the i/o issues themselves, there is also the cpu cost of performing buffered i/o. This becomes more important when moving data around at rates greater than 100MB/s. The combination of direct i/o, multithreading and large buffer sizes excels here. There can be a few remaining HW- and platform-specific wrinkles to attend to, such as using large pages where possible to reduce DTLB misses, and choosing carefully the alignment of the start of the buffer, such as being page-aligned.
Excellent follow up Richard! Thanks. I do have a question to pose back at you though. Somehow I cannot imagine mmap functioning on a forcedirectio file. Can you confirm whether Solaris cp has intelligence built in such that if it determines the file is a direct I/O file it does in fact (or not) revert to using read instead?
Also, I’m confused as to whether your post is in opposition to the theme of my blog entry which is in fact that copying around large files that are not going to be shared (e.g., archived Oracle redo logs, backups, etc) would be better moved about without perturbing the page cache. you say:
“This becomes more important when moving data around at rates greater than 100MB/s. The combination of direct i/o, multithreading and large buffer sizes excels here.”
…and I couldn’t agree with you more. That comment is, in fact, the reason I blogged about this topic–although I don’t necessarily think multithreading is as important as you suggest in this particular situation (copying files). It doesn’t take many CPU cycles to get a LOT of data moving around…after all, cp(1) doesn’t actually look at the contents of its buffers, it merely “reads” (implementation specific as we’ve discussed) and writes. I could see the concern over multithreading (particularly on something like Niagra) if cp(1) in fact actually looked at the buffer contents after it reads and before it writes. I my have to blog this very point …
Readers,
Regarding cp(1) on forcedirectio UFS, I was just informed on a side-channel discussion with a friend that mmap is indeed functional on a forcedirectio mount. That is surprising to me, but it is mostly trivial pursuit. the important point is that at least on solaris, you don’t have little itsy-bitsy read requests…
open64(“SYSLOG-4”, O_RDONLY) = 3
creat64(“xxx”, 0777) = 4
stat64(“xxx”, 0x00028640) = 0
fstat64(3, 0x000286D8) = 0
mmap64(0x00000000, 6161922, PROT_READ, MAP_SHARED, 3, 0) = 0xFEC00000
write(4, ” F e b 5 1 0 : 3 6″.., 6161922) = 6161922
munmap(0xFEC00000, 6161922) = 0
this means that the file was mapped in its entirety, paged in and written… good stuff…takes more memory than I’d like though if copying things like archived redo… maybe someone will chime in with information about what cp(1) does if the file is huge…must map and unmap but where is the cut-off? This was a ~5MB file and it performed the mmap-enabled cp(1) in one swoop…hmmm…
Solaris cp on SPARC actually remaps successive 8MB chunks to the same virtual address, so it doesn’t necessarily use a huge amount of memory. In principle one could imagine various alternate memory management strategies, for example continually grabbing a supply of pages from a free page list, but when a sequential i/o pattern is detected it makes more sense to reuse the same real memory.
mmap64(0xFE800000, 8388608, PROT_READ, MAP_SHARED|MAP_FIXED, 3, 0x02800000) = 0xFE800000
write(4, “FBDAC5 q81B1 &F9 NBAC7 X”.., 8388608) = 8388608
mmap64(0xFE800000, 8388608, PROT_READ, MAP_SHARED|MAP_FIXED, 3, 0x03000000) = 0xFE800000
write(4, “EA 31B 0 qD393A7 U + lD0”.., 8388608) = 8388608
…
Perhaps I misinterpreted the theme: I certainly encourage the use of direct i/o, but I’m aware how utilities with woefully inadequate i/o buffers can cause problems. For that matter, many of the customers I deal with don’t know how to interpret iostat data, and for them performance is a “black box”. Without help, they’re unaware of the extent of the problem.
One reason I raised multithreading as an issue is the challenge of maximising throughput. Ideally you’d like to be able to drive either the source or the sink 100% busy. An example is the case of backing up to a tape drive, where you’d like to keep the tape drive streaming. If the source is being read via direct i/o and then written in a single thread, it is highly likely that neither end is kept 100% busy.
I encountered this with a customer complaining about the time it was taking them to do a backup and suspecting something was wrong with the tape subsystem. Of course, running a few very simple tests, like reading from /dev/zero and writing to tape (perfectly compressible) showed what the tape could do if supplied fast enough. Therein lay the problem, that the data wasn’t being sourced fast enough. Using large i/o buffers and a multithreaded utility like star made a huge difference.
With respect to cpu time, I don’t think the cost is associated with moving the bytes into or out of a buffer per se, but rather the entire code path or set of instructions that have to be executed. In some of the cases I’ve investigated, the cpu time cost was sufficient to represent a significant component of the elapsed time. As always though, its a good idea to measure it, so that its contribution is known. I suggest 100MB/s as a reasonable number where you might want to pay some attention to it.
Richard writes: “Perhaps I misinterpreted the theme: I certainly encourage the use of direct i/o, but I’m aware how utilities with woefully inadequate i/o buffers can cause problems.”
Richard,
The whole blog thread is about the attention to detail necessary to live with direct I/O given certain file utilities nibble on I/O. That is why I discussed the concepts used in the cp8M program in the post. So you are aware, and I am aware and together we can hopefully make others aware. In the end, I think it is COMPLETELY INSANE that modern system ship with OS file tools that nibble on I/O with such ridiculous I/O sizes as 4KB and so on…but, gain, that is exactly what I’m blogging about in this thread.
Richard writes: “but when a sequential i/o pattern is detected it makes more sense to reuse the same real memory.”
… now that comment is interesting. Tell me, wouldn’t starting the program with an 8MB buffer from malloc() and re-using it as the buffer arg to pread() be “the same real memory?” Yes, of course it would. In fact, constantly executing mmap()(and jostling the address space) seems to me a lot more expensive than using the same heap buffer and advancing the file pointer, but I don’t have a solaris system to benchmark the difference between the cp8M program above and the stock Solaris cp(1) command. Anyone care to volunteer?
All,
I came across this and other discussions by author looking for a solution to a Solaris cp issue.
My office has a Themis Solaris 8 server and I have a Sun280R, 2 D1000 and a 2TB RAID.
THe data management guys reported a drastic slowdown in xfer speed transfering the contents from several 300Gb SCSI drives to the RAID. I mocked up my Sun280 to the same type of configuration and encountered the same behavior. I set up a 3rd test configuration using a Blade 100, a D1000 and a Arena Industrial 2TB raid. All 3 have the same dramantic slowdown.
I wrote a script to mount the RAID, echo mount time, mount the first 300gb drive, echo mount time, cp the contents from the 300gb drive to the RAID, echo time when transfer is complete, unmount 300gb drive, mount the next 300gb drive echo time transfer and so on.
The first 300gb transfer takes approx 2 hours, the 2 over 3 hours the 4th over 8 hours. All 3 platforms have the same behavior. The Themis in on Solaris 8. The Sun280 and Blace 100 are on Solaris 10.
There seems to be a memory or buffering issue with the “cp” program and wonder if anyone else has seen this and knows of a fix.
Thanks
Please respond to email address also.
Thanks