The problem with blogging is there is no way to clearly write something tongue-in-cheek. No facial expressions, no smirking, no hand waving—just plain old black and white. That aside, I can’t resist posting a follow-up to a post on StorageMojo about ZFS performance. I’m not taking a swipe at StorageMojo because it is one of my favorite blogs. However, every now and again third party perspective is a healthy thing. The topic at hand is this post about ZFS performance which is a digest of this post on digitalbadger.net. The original post starts with:
I have seen many benchmarks indicating that for general usage, ZFS should be at least as fast if not faster than UFS (directio not withstanding)[…]
Right off the bat I was scratching my head. I have experience with direct I/O dating back to 1991 and have some direct I/O related posts here. I was trying to figure out what the phrase “directio not withstanding” was supposed to mean. The only performance boost direct I/O can possibly yield is due to the elimination of the write-ordering locks generally imposed by POSIX and the double-buffering/memcopys overhead associated with the DMA into the page cache—and subsequent copy into the user address space buffer. So for a read-intensive benchmark, about the only thing one should expect is less processor overhead, not increased throughput.
Anyway, the post continues:
To give a little background : I have been experiencing really bad throughput on our 3510-based SAN. The hosts are X4100s, 12Gb RAM, 2x dual core 2.6Ghz opterons and Solaris 10 11/06. They are each connected to a 3510FC dual-controller array via a dual-port HBA and 2 Brocade SW200e switches, using MxPIO. All fabric is at 2Gb/s […]
OK, the 4100 is a 2-way Opteron 2000 server which, being a lot like an HP Proliant DL385, should have no problem consuming all the data the 2 x 2Gb FCP paths can deliver—roughly 400MB/s. If the post is about a UFS versus ZFS apples-apples comparison, both results should top out at the maximum theoretical throughput of 2x2Gb FCP. The post continues:
On average, I was seeing some pretty average to poor rates on the non-ZFS volumes depending on how they were configured, on average I was seeing 65MB/s write performance and around 450MB/s read on the SAN using a single drive LUN.
I’d be plenty happy with that 450MB/s given that configuration. The post insinuates this is direct I/O so getting 450MB/s out of 2x2Gb FCP should be the end of the contest. Further, getting 65MB/s written to a single drive LUN is quite snappy! What is left to benchmark? It seems UFS cranks the SAN at full bandwidth.
The post continues:
I then tried ZFS, and immediately started seeing a crazy rate of around 1GB/s read AND write, peaking at close to 2GB/s. Given that this was round 2 to 4 times the capacity of the fabric, it was clear something was going awry.
Hmmm…Opterons with HT 2.0 attaining peaks of 2GB/s write throughput via 2x2Gb FCP? There is nothing awry about this, it is simply not writing the data to the storage.
This is a memory test. ZFS is caching, UFS is not.
The post continues:
Many thanks to Greg Menke and Tim Bradshaw on comp.unix.solaris for their help in unravelling this mystery!
What mystery? I’d recommend testing something that runs longer than 1 second (reading 512MB from memory on any Opteron system should take about .6 seconds. I’d recommend a dataset that is about 2 fold larger than physical memory.
How Does ZFS and UFS Compare to Other Filesystems?
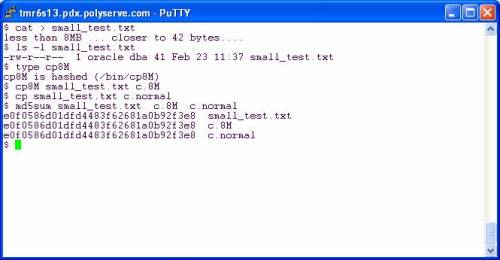
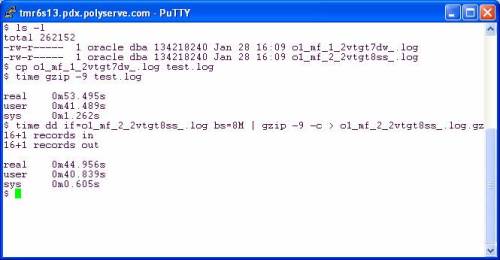
Let’s take a look at an equivalent test running on the HP Cluster Gateway internal filesystem (the former PolyServe PSFS). The following is a screen shot of a dd(1) test using real Oracle datafiles on a Proliant DL585. The first test executes a single thread of dd(1) reading the first 512MB of one of the files using 1M read requests. The throughput is 815MB/s. Next, I ran 2 concurrent dd(1) processes each chomping the first 512MB out of two different Oracle datafiles using 1MB read requests. In the concurrent case, the throughput was 1.46GB/s.
NOTE: You may have to right click->view the image.

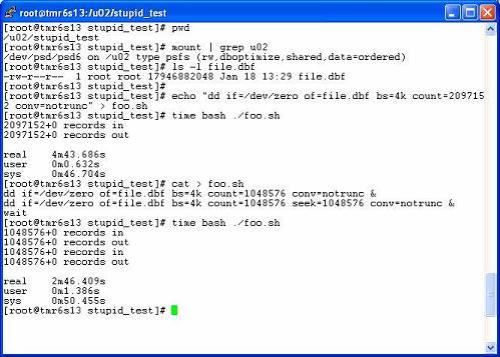
But wait, in order to prove the vast superiority of the HP Cluster Gateway filesystem over ZFS using similar hardware, I fired off 6 concurrent dd(1) processes each reading the first 512MB out of six different files. Here I measured 2.9GB/s!









Recent Comments