If Sir Isaac Newton was walking about today dropping apples to prove his theory of gravity, he’d feel about like I do making this blog entry. The topic? Concurrent writes on file system files with Direct I/O.
A couple of months back, I made a blog entry about BIGFILE tablespaces in ASM versus modern file systems.The controversy at hand at the time was about the dreadful OS locking overhead that must surely be associated with using large files in a file system. I spent a good deal of time tending to that blog entry pointing out that the world is no longer flat and such age-old concerns over OS locking overhead on modern file systems no longer relevant. Modern file systems support Direct I/O and one of the subtleties that seems to have been lost in the definition of Direct I/O is the elimination of the write-ordering locks that are required for regular file system access. The serialization is normally required so that if two processes should write to the same offset in the same file, one entire write must occur before the other—thus preventing fractured writes. With databases like Oracle, no two processes will write to the same offset in the same file at the same time. So why have the OS impose such locking? It doesn’t with modern file systems that support Direct I/O.
In regards to the blog entry called ASM is “not really an optional extra” With BIGFILE Tablespaces, a reader posted the following comment:
“node locks are only an issue when file metadata changes”
This is the first time I’ve heard this. I’ve had a quick scout around various sources, and I can’t find support for this statement.
All the notes on the subject that I can find show that inode/POSIX locks are also used for controlling the order of writes and the consistency of reads. Which makes sense to me….Refer to:
http://www.ixora.com.au/notes/inode_locks.htmSec 5.4.4 of
http://www.phptr.com/articles/article.asp?p=606585&seqNum=4&rl=1Sec 2.4.5 of
http://www.solarisinternals.com/si/reading/oracle_fsperf.pdfTable 15.2 of
http://www.informit.com/articles/article.asp?p=605371&seqNum=6&rl=1Am I misunderstanding something?
And my reply:
…in short, yes. When I contrast ASM to a file system, I only include direct I/O file systems. The number of file systems and file system options that have eliminated the write-ordering locks is a very long list starting, in my experience, with direct async I/O on Sequent UFS as far back as 1991 and continuing with VxFS with Quick I/O, VxFS with ODM, PolyServe PSFS (with the DBOptimized mount option), Solaris UFS post Sol8-U3 with the forcedirectio mount option and others I’m sure. Databases do their own serialization so the file system doing so is not needed.
The ixora and solarisinternals references are very old (2001/2002). As I said, Solaris 8U3 direct I/O completely eliminates write-ordering locks. Further, Steve Adams also points out that Solaris 8U3 and Quick I/O where the only ones they were aware of, but that doesn’t mean VxFS ODM (2001), Sequent UFS (starting in 1992) and ptx/EFS, and PolyServe PSFS (2002) weren’t all supporting completely unencumbered concurrent writes.
Ari, thanks for reading and thanks for bringing these old links to my attention. Steve is a fellow Oaktable Network Member…I’ll have to let him know about this out of date stuff.
There is way too much old (and incomplete) information out there.
A Quick Test Case to Prove the Point
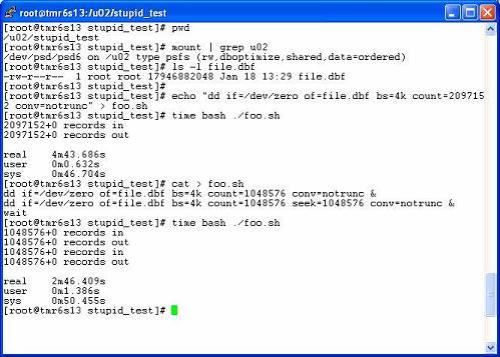
The following screen shot shows a shell process on one of my Proliant DL585s with Linux RHEL 4 and the PolyServe Database Utility for Oracle. The session is using the PolyServe PSFS filesystem mounted with the DBOptimized mount option which supports Direct I/O. The test consists of a single dd(1) process overwriting the first 8GB of a file that is a little over 16GB. The first invocation of dd(1) writes 2097152 4KB blocks in 283 seconds for an I/O rate of 7,410 writes per second. The next test consisted of executing 2 concurrent dd(1) processes each writing a 4GB portion of the file. Bear in mind that the age old, decrepit write-ordering locks of yester-year serialized writes. Without bypassing those write locks, two concurrent write-intensive processes cannot scale their writes on a single file. The screen shot shows that the concurrent write test achieved 12,633 writes per second. Although 12,633 represents only 85% scale-up, remember, these are physical I/Os—I have a lot of lab gear, but I’d have to look around for a LUN that can do more than 12,633 IOps and I wanted to belt out this post. The point is that on a “normal” file system, the second go around of foo.sh with two dd(1) processes would take the same amount of time to complete as the single dd(1) run. Why? Because both tests have the same amount of write payload and if the second foo.sh suffered serialization the completion times would be the same:



Actually, the solarisinternals.com page on direct I/O at http://www.solarisinternals.com/wiki/index.php/Direct_I/O is fairly recent. Since its a Twiki, it’s not necessarily static.
There seems to be perpetual confusion over ‘direct I/O’, and much of it arises from the fact ‘direct I/O’ does not carry the same implications in all its various implementations. All direct I/O implementations are unbuffered, but not all give write concurrency. The UFS direct I/O implementation in the Solaris OS gives concurrency, but most other filesystems do not deliver concurrency with their basic direct I/O features. VxFS direct I/O (such as with ‘convosync=direct,mincache=direct’ for example, is a ‘direct I/O’ option that does *not* deliver concurrency. Therefore, you might want to tweak the title of your blog entry.
I’m not familiar with PolyServe PSFS, but I’d geneally caution against using dd for I/O benchmarking writes. dd does not use O_DSYNC as Oracle does, so it might not create results representative of what Oracle would see. Also, sustained writing performance can vary a great deal depending on whether a file is being extended, due to the increased metadata overhead. Write performance can even vary with the O_DSYNC option, since it’s a different code path that might optimize some things but not others. For example, in the Solaris OS, file extends on UFS files using O_DYSNC are abysmally slow.
There’s a lot of nuisance detail around these topics, but it’s all explainable. Stuff like this is what I try to square in my papers and my blog. We should compare notes offline sometime.
Best regards,
— Bob
Bob,
Thanks for stopping by. Yes, there are a lot of differences from platform to platform on whether or not you get both concurrent and direct when using “direct I/O”. You called out VxFS as a filesystem that serves as proof I missed the point and yet but I specifically state in my post that VxFS requires Quick I/O or ODM for concurrent+direct. I’ll quote myself:
“The number of filesystems and filesystem options that have eliminated the write-ordering locks is a very long list starting, in my experience, with direct async I/O on Sequent UFS as far back as 1991 and continuing with VxFS with Quick I/O, VxFS with ODM, PolyServe PSFS with the DBOptimized mount option, Solaris UFS post Sol8-U3 ”
Further, your comment about O_DSYNC is platform specific. On Linux O_DSYNC isn’t how LGWR does it because O_DSYNC is not a supported Linux open(2) flag. With Linux, O_SYNC is exactly the same as O_DSYNC (man 2 open). But we are talking direct I/O so writes are synced anyway.
I stand by using dd as a concurrent write stimulus for the sake of making my point in this blog entry. The point wasn’t to precisely mimic Oracle, but instead to use a clear simple case to show that the particular filesystem in question did not impose write-ordering locks.
Finally, your recommendation to be mindful of the impact file extend operations levy on writes is not very relevant in an Oracle context for 2 reasons; 1) Oracle does not allow any writes in flight when a datafile is extending (all I/O is quiesced before the file extend) and 2) log files do not auto-extend.
Having worked on the internals of 5 different Oracle ports (68030 Unix, Altos System V, Dynix (BSD) and DYNIX/ptx (SysV) and Solaris) I strive to be as accurate as possible when discussing the OSDs. So please, by all means, continue to read the blog and enrich the threads with your questions.
“VxFS direct I/O (such as with ‘convosync=direct,mincache=direct’ for example, is a ‘direct I/O’ option that does *not* deliver concurrency.”
That is exactly how my vxfs partitions are mounted (on RHEL4). 😦
I take it I should be looking into ODM?
Like I tried to point out to Bob Sneed, VxFS requires either Quick I/O or ODM for non-serialized writes…but you are on Linux…you could also just use a “real file system” with O_DIRECT 🙂
Looks like you’re right. Greg Rahn had me do an strace and it confirmed that we’re using async (from the presence of io_submit and io_getevents).
I am not sure if this thread is still active. I have a quicvk question and need a answer, thanks.
Question: Does VxFS (Solaris) with convosync=direct eliminate the single-writer lock for an application which does not use O_SYNC?