Yesterday I posted a blog entry about copying files on Solaris. I received some side channel email on the post such as one with the following tidbit from a very good, long time friend of mine. He wrote:
So optimizing cp() is now your hobby? What’s next….. “ed”… no wait “df”.. boy it sure would be great if I could get a 20% improvement in “ls”… I am sure these commands are limiting the number of orders/hr my business can process :)))
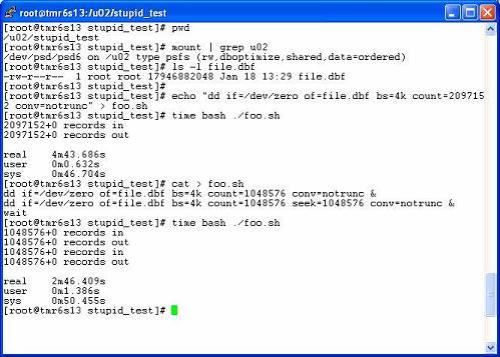
Didn’t that blog entry show a traditional cp(1) implementation utilizing 26% less kernel mode processor cycles? Oh well.
It’s About the Whole System
While those were words spoken in jest, it warrants a blog entry and I’ll tell you why. It is true this is an Oracle related blog and such filesystem tools as cp(1) are not in the Oracle code path. I blog about these things for two reasons: 1) a lot of my readers enjoy learning more about the platform in general and 2) many—perhaps most—Oracle systems have normal file system tools such as cp(1), compress(1) and others running while Oracle is running. For that matter, the Oracle server can call out to the same libraries these tools use for such functionality as BFILE and UTL_FILE. For that reason, I feel these topics are related to Oracle platforms. After all, a garbage-can implementation of the standard filesystem tools—and/or the kernel code paths that service them—is going to take cycles away from Oracle. Now please don’t quote me as saying the mmap()-enabled Solaris cp(1) is a “garbage-can” implementation. I’m just making the point that if such tools are implemented poorly Oracle can be affected even though they are not in the scope of a transaction. It’s about the whole system.
Legacy Code. What Comes Around…Stays Around.
Let’s not think for even a moment that the internals of such tools as ls(1) and df(1) are beyond scrutiny. Both ls(1) and df(1) use the stat(2) system call. We Oracle-minded folks often forget that there is much more unstructured data than structured so it is a good thing there are still some folks like PolyServe (HP) minding the store for the performance of such mundane topics as stat(2). Why? Well, perfect examples are the online photo operations such as Snapfish. Try having thousands of threads accessing tens of millions of files (photos) for fun. See, Snapfish uses the HP Enterprise File Services Clustered Gateway NAS powered by PolyServe. You can bet we pay attention to “mundane” topics like what ls(1) behaves like in a directory with 1, 2 or 100 million small files. The stat(2) system call is extremely important in such situations.
He’s Off His Rocker—This is an Oracle Blog.
What could this possibly have to do with Oracle? Well, if you run Oracle on a platform that only specializes in the code underpinnings of the most common server I/O (e.g., db file sequential read, db file scattered read, direct path read/write, LGWR and DBWR writes), you might not end up very happy if you have to do things that hammer the filesystem with Oracle features like UTL_FILE, BFILE, external tables, imp/exp and so forth, cp(1), tar(1), compress(1) and so on. It’s all about taking a holistic view instead of “camps” that focus on segments of the I/O stack.
As the cliché goes, standard file operations and highly specialized Oracle code paths are often joined at the hip.



Recent Comments