If you have an Linux system, check the “bugs” section of the man page for the open(2) system call and you’ll see the following quote from Linus Torvalds:
The thing that has always disturbed me about O_DIRECT is that the whole interface is just stupid, and was probably designed by a deranged monkey on some serious mind-controlling substances -Linus
I’m not joking, read that man page and you’ll see. Now, while I much prefer a mount option approach to direct I/O, I don’t think the O_DIRECT style of direct I/O was the brain child of a deranged monkey. I wonder if Linus is insinuating that the interface would be better if it was written by a sane monkey—or perhaps even a deranged monkey that is not on some serious mind-controlling substances?
There is nothing strange about O_DIRECT and most of the Unix derivations I am aware of are happy to offer it (Solaris being the notable exception offering directio(3C) instead). I’d love to know more about the context of that Linus quote. I’ve been around O_DIRECT since the very early 1990s. Sequent supported O_DIRECT opens on DYNIX/ptx file system files way back in 1991.
The Linux kernel development community still languishes over the fact that software like Oracle does not like to kernel-dive to access buffered data, preferring to do its own buffering instead.
A Mount-Option Approach
Why? Well, if you have programs that perform properly aligned I/O calls (e.g., cat(1), dd(1), cp(1), etc) but you don’t want them “polluting “ your system page cache, then you either need a mount-option approach to do Direct I/O or the tools need to be re-coded to open O_DIRECT. Back in 2001 I had the opportunity to make that choice for PolyServe and I haven’t regretted it once. Let me explain.
Let’s say, for instance, you generate and compress a few gigabytes of archived redo logs per day—or roughly ~40KB per second. It doesn’t sound like much, I know. But let’s look at page cache costs. When ARCH spools an offline redo log to the archive log destination the OS page cache will be used to buffer the I/O. When your compression tool (e.g. compress(P), gzip(1)) reads the file, page cache will once again be used. As the output of compress needs to be written page cache is used. Finally, when the archived redo is copied off the system (e.g., to tape), page cache will again be used. All this caching for data that is not used again—save for emergencies. But really, caching sequentially read archived files and compress output? Makes little sense.
The only way to not cache this sort of data is O_DIRECT, but I/Os issued against an O_DIRECT opened file must be multiples of the underlying disk block size (generally 512 bytes). The buffer in the calling process used for the I/O must also be a aligned on an address that is a multiple of the OS page size. It turns out that most OS tools perform proper alignment of their I/O buffers. So where is the rub? The I/O sizes! Even if you coded your compress tool to use O_DIRECT (deranged monkey syndrome), the odds that the output file will be a multiple of 512 bytes is nil. Let’s look at an example.
Direct I/O for Better Memory Utilization
In the following session I performed 6 steps to see the effect of direct I/O:
- Use df to determine space and exact filesystem of my current working directory (CWD)
- Check the Mount options. My CWD is a PolyServe PSFS mounted with the DBOptimized mount option which “renders” direct I/O akin to the Solaris –forcedirectio mount option.
- List my redo logs. Note, they are OMF files so the names are a bit strange.
- Check free memory on the system
- Copy a redo log
- Check free memory again to see how much memory was used by the OS page cache

OK, hold it, in step 5 I copied a 128MB file and yet the free memory available only changed by 176KB (from step 4 to step 6). My copy of an online log closely resembles what ARCH does—it simply copies the inactive online redo log to the archive log destination. I like the ability to not consume 256MB of physical memory to copy a file that is no longer really part of the database! The cp(1) command performs I/O with requests that are 512byte multiples, so the PolyServe CFS mounted in the DBOptimized mode simply “renders” the I/O through the direct I/O code path. No, cp(1) does not open with O_DIRECT, yet I relieved the pressure on free memory by copying with Direct I/O via the mount option. That’s good.
File Compression with Direct I/O Mounted Filesystem
But what about compressing files in a direct I/O filesystem? Let’s take a look. In the next session I did the following:
- Check free memory on the system
- Used ls(1) to see my copy of the redo log file.
- Used gzip(1) with maximum compression on the copy of the redo log file
- Used ls(1) to see the file size of the compressed file.
- Check free memory on the system to see what OS page cache was used
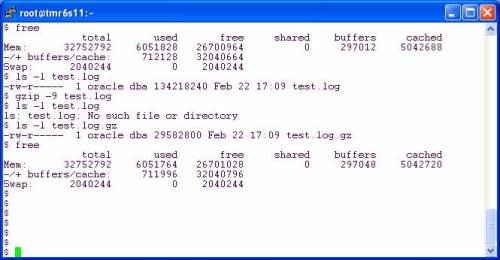
OK, this is good. I take a 128MB redo log file and compress it down to 29,582,800 bytes—which is, of course, 57,778 512 byte chunks plus one 464 byte chunk. According to the differences in free memory from step 1 and step 5, only 64KB of system memory was “wasted” in the act of compressing that file. Why do I say wasted? Because cache is best used for sharing data such as in the SGA, however, here I was able to read in 128MB and write out 28.2MB and only used 64KB of page cache in the process. Memory costs money and efficiency matters. This is the reason I prefer a mount option approach to direct I/O.
Back to the example. How did I write an amount that included a stray 464 bytes with direct I/O? That is not a multiple of the underlying disk driver requirement which is 512 bytes.
Under The Covers
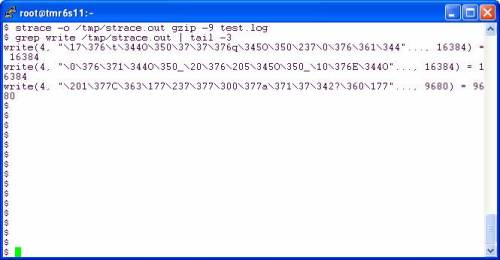
On Linux, gzip(1) uses 32KB reads and 16KB writes. The output file created by gzip(1) is 29,839,295 bytes which is 1,805 writes at 16KB and one last odd-ball write of 9,680 bytes—something that would be impossible to do with direct I/O were it not for the direct I/O mount option. Let’s look at strace. The last write was 9,680 bytes:
Direct I/O Without Compile-Time O_DIRECT
I can’t speak about other direct I/O mount implementations, but I can explain how PolyServe does this. All I/O bound for files in a DBOptimized mounted PSFS filesystem are quickly examined to see if the I/O meets the underlying device driver DMA requirements. In the kernel we use simple arithmetic to determine if the I/O size is a multiple of the underlying disk block size (satisfies DMA requirement) and whether the I/O buffer is aligned on a page boundry. If both conditions are true, the I/O is DMAed directly from the process address space to the disk. If not, we simply grab an OS page cache buffer, perform the I/O and then immediately invalidate that page so no other process can read dirty data (PolyServe is sort of big on cache coherency if you get my drift).
Best of Both Worlds
In the end, Linus might be right about O_DIRECT, but sitting here at PolyServe makes me say, “Who cares.” We supported direct I/O on Linux before Linux supported O_DIRECT (it was just a patch at that time). In fact, we did a 10-node Oracle9i RAC, 10 TB, 10,000 user OLTP Proof of Concept way back in 2002—before Linux O_DIRECT was mainstream. Here is a link to the paper if you are interested in that proof point.



I’ve noticed that on Solaris filesystems with forcedirectio , a “compress” becomes quite
significantly slower. I had a database where
I was doing disk-based backups and if I did “cp” and “compress” scripting to a forcedirectio filesystem the database backup would be about twice as long as one on a normally mounted filesystem.
Hemant
Hemant,
that’s because when the OS does buffering, it prefetches
clusters of pages from disk. With directio, the data is
DMAd directly to the user buffer. There is nowhere to
store any prefetched data because there is no API for
the user to specify a second buffer (for the unrequested
prefetched component of the cluster) and to buffer the
prefetched data in the kernel would not be “direct” io.
Moral of the story is to use an appropriately sized buffer
with directio. stdio based utilities use tiny buffers.