Here is a chuckle from our local rag. I wonder if the editor learned about the internets from President Bush or Al Gore—the supposed self-proclaimed inventor of the internet—a claim mistakingly attributed to Gore.

Platform, Database and Storage Topics
Here is a chuckle from our local rag. I wonder if the editor learned about the internets from President Bush or Al Gore—the supposed self-proclaimed inventor of the internet—a claim mistakingly attributed to Gore.
When I first started blogging I was told that it is important to blog regularly-so I did. I’ve made over 170 posts that WordPress recons have been viewed some 200,000 times. But then my former company, PolyServe, got bought by HP. My blogging rate has plummeted, but the search engines seem to still be piling in the readers.
I am not blogging as frequently because, honestly, I can’t figure out the balance between political correctness and interesting content. That is, I’m a bit overwhelmed trying to assimilate into HP culture. I don’t know what I can safely blog about without getting someone upset in the eleventeen layers of management between me and Mark Hurd (HP CEO). I remember feeling this way back in 1999 when Sequent (where I had done port-level Oracle work for some 10 years) got bought by IBM.
The HP folks that maintain their blogroll invited me to complete a 30 minute training session on blogging at HP so they can list my blog there. I haven’t gotten around to that yet.
Old Topics
I still have the final installment on my series on NUMA in the bull-pen. I think I’ll pound that one out today or tomorrow. In the meantime, how about some fluff.
Geek-free Topic
Over the Memorial Day weekend, the family and I joined up with my age-old friend Tom for some camping on his family’s ranch. With 2005 acres to stretch out in, camping on his ranch is what I call peace and quiet. Wildlife viewing is unbelievable up there. We saw well over 200 elk, dozens of deer, troops of wild turkeys, coyotes and a few rattlesnakes. The water was a little low for fishing, but we picked up some trout anyway. I’ll drop some photos in here.




I ran across an interesting quote on www.perl.com that challenged my appreciation of relational database technology—and most particularly Oracle. The article states:
Relational databases started to get to be a big deal in the 1970’s, and they’re still a big deal today, which is a little peculiar, because they’re a 1960’s technology.
Forget the “started to get to be” bit for a moment. Uh, yes, RDBMS technology became important in the 70s (ISI, PRTV and Honeywell MRDS). However, since E.F. Codd didn’t write the defining paper until 1970 it is a stretch to call it “1960’s technology.” Oh well, that perl.com article was written in 1999 after all.
What a Great Idea: I Want to Force Some New, “Cool” Technology into My IT Shop
The bit in the quote that got me thinking was how astonished the author was that 1960’s—well, 1970’s actually—technology was “still a big deal” way back in 1999. You see, I think one thing that actually hurts IT shops is the nearly absurd rate of new technology injection. It seems to me that the datacenters with the highest level of success are those that take new technology as slowly as possible. Am I talking about newer versions of, say, the Oracle database server? No, absolutely not. Adopting a newer revision of Oracle is not radical. Those of us who revere the code rest soundly at night knowing that deep down in kernel are bits and pieces that haven’t really changed much in the last 20+ years—perhaps even 30 years given the KCB role in multi-block read consistency (if in fact MBRC was there in the first version of Oracle).
Why is there a mindset in IT that all old technology must go? Folks, we still use little round, brown spinning things (hard drives). Now there’s a bit of information technology that has been around longer than relational databases and ripe for a fond farewell. DBAs are asking for “disk space” from their storage administrators and that is exactly what they are getting. Forget for a moment that roughly 30 drives worth of large, sequential read throughput can saturate the bandwidth of most high-end FC SAN array controllers. Yes, there are exceptions, but I’m trying to make a point. The point is, here we are 27 years after the introduction of the ST506 5.25” and we are not getting full utilization of our drives—at least not when they are provisioned the way most space is provisioned these days. That is, you ask for 2TB of “space” for your Oracle database and you get it—allocated from something like 6 disks in the same enclosure as dozens of other disks. You are getting space, not bandwidth.
What’s This Have to Do with Oracle?
Someone should ask the author of that perl.com article if old technology deserves the rubbish heap simply because it is old. Ask him if he has tires on his car (powered with an internal-combustion engine no less). Yep, pneumatic tires for cars date back to P. Strauss circa 1911. No, really, what does this have to do with Oracle? You see, it is software from companies like Oracle—with their “old” RDBMS front and center—that will first help us tackle this problem we have with untapped hard-drive bandwidth and eventually move us along to whatever replaces those little, round brown spinning things in the future. Yes I am hinting, but I’m not saying anything more.
That’s right, that old crusty Oracle RDBMS technology—created to efficiently manage data stored on hard drives—will outlive hard drives and, quite likely, whatever replaces hard drives. That isn’t so hard to accept. After all, P. Strauss’ pneumatic tire will certainly be getting us to and fro long after we move beyond the internal combustion engine.
Dry, Techno-Geek Humor
The perl.com article also contained some humor. The following definition was given for what an RDBMS is:
A relational database is a bunch of rectangular tables. Each row of a table is a record about one person or thing; the record contains several pieces of information called fields.
Couldn’t a table be square? Somebody please tell that guy that tables have columns (attributes). Files, being hierarchical, have fields.
…President George H.W. Bush that is…
It’s amazing what one finds when cleaning out old papers and things…
I was clearing out some old office files when I found a program from a conference I spoke at back in 1999. The conference was the IBM Enterprise Solutions Summit in San Diego—out on Coronado Island. I just had to scan this one in—and blog it for that matter. You’ll see the key note for the day was President Bush and on the right hand of the program detailed my session from 2-3PM. Ahhh Memories….
NOTE: For clarity, right click->view the image. Note, Firefox will allow you to zoom in too:

I assert that Oracle over NFS is not going away anytime soon—it’s only going to get better. In fact, there are futures that make it even more attractive from a performance and availability standpoint, but even today’s technology is sufficient for Oracle over NFS. Having said that, there is no shortage of misunderstanding about the model. The lack of understanding ranges from clear ignorance about the performance characteristics to simple misunderstanding about how Oracle interacts with the protocol.
Perhaps ignorance is not always the case when folks miss the mark about the performance characteristics. Indeed, when someone tells me the performance is horrible with Oracle over NFS—and the say they actually measured the performance—I can’t call them a bold-faced liar. I’m sure nay-sayers in the poor-performance crowd saw what they saw, but they likely had a botched test. I too have seen the results of a lot of botched or ill-constructed tests, but I can’t dismiss an entire storage and connectivity model based on such results. I’ll discuss possible botched tests in a later post. First, I’d like to clear up the common misunderstanding about NFS and Oracle from a protocol perspective.
The 800lb Gorilla
No secrets here; Network Appliance is the stereotypical 800lb gorilla in the NFS space. So why not get some clarity on the protocol from Network Appliance’s Dave Hitz? In this blog entry about iSCSI and NAS, Dave says:
The two big differences between NAS and Fibre Channel SAN are the wires and the protocols. In terms of wires, NAS runs on Ethernet, and FC-SAN runs on Fibre Channel.
Good so far—in part. Yes, most people feed their Oracle database servers with little orange glass, expensive Host Bus Adaptors and expensive switches. That’s the FCP way. How did we get here? Well, FCP hit 1Gb long before Ethernet and honestly, the NFS overhead most people mistakenly fear in today’s technology was truly a problem in the 2000-2004 time frame. That was then, this is now.
As for NAS, Dave stopped short by suggesting NAS (e.g., NFS, iSCSI) runs over Ethernet. There is also IP over Infiniband. I don’t believe NetApp plays Infiniband so that is likely the reason for the omission.
Dave continues:
The protocols are also different. NAS communicates at the file level, with requests like create-file-MyHomework.doc or read-file-Budget.xls. FC-SAN communicates at the block level, with requests over the wire like read-block-thirty-four or write-block-five-thousand-and-two.
What? NAS is either NFS or iSCSI—honestly. However, only NFS operates with requests like “read-file-Budget.xls”. But that is not the full story and herein comes the confusion when the topic of Oracle over NFS comes up. Dave has inadvertently contributed to the misunderstanding. Yes, an NFS client may indeed cause NFS to return an entire Excel spreadsheet, but that is certainly not how accesses to Oracle database files are conducted. I’ll state it simply, and concisely:
Oracle over NFS is a file positioning and read/write workload.
Oracle over NFS is not traditional “file serving.” Oracle on an NFS client does not fetch entire files. That would simply not function. In fact, Oracle over NFS couldn’t possibly have less in common with traditional “file serving.” It’s all about Direct I/O.
Direct I/O with NFS
Oracle running on an NFS client does not double buffer by using both an SGA and the NFS client page cache. All platforms (that matter) support Direct I/O for files in NFS mounts. To that end, the cache model is SGA->Storage Cache and nothing in between—and therefore none of the associated NFS client cache overhead. And as I’ve pointed out in many blog entries before, I only call something “Direct I/O” if it is real Direct I/O. That is, Direct I/O and concurrent I/O (no write ordering locks).
I/O Libraries
Oracle uses the same I/O libraries (in Oracle9i/Oracle10g) to access files in NFS mounts as it does for:
Oops, I almost forgot, there is also Oracle Disk Manager. So let me restate. When Oracle is not linked with an Oracle Disk Manager library or ASMLib, the same I/O calls are used for all of the storage options in the list I just provided.
So what’s the point? Well, the point I’m making is that Oracle behaves the same on NFS as it does on all the other storage options. Oracle simply positions within the files and reads or writes what’s there. No magic. But how does it perform?
The Performance is Glacial
There is a recent thread on comp.databases.oracle.server about 10g RAC that wound up twisting through other topics including Oracle over NFS. When discussing the performance of Oracle over NFS, one participant in the thread stated his view bluntly:
And the performance will be glacial: I’ve done it.
Glacial? That is:
gla·cial
adj.
1.
a. Of, relating to, or derived from a glacier.
b. Suggesting the extreme slowness of a glacier: Work proceeded at a glacial pace.
Let me see if I can redefine glacial using modern tested results with real computers, real software, and real storage. This is just a snippet, but it should put the term glacial in a proper light.
In the following screen shot, I list a simple script that contains commands to capture the cumulative physical I/O the instance has done since boot time followed with a simple PL/SQL block that performs full light-weight scans against a table followed by another peek at the cumulative physical I/O. For this test I was not able to come up with a huge amount of storage so I created and loaded a table with order entry history records—about 25GB worth of data. So that the test runs for a reasonable amount of time I scan the table 4 times using the simple PL/SQL block.
NOTE: You may have to right click-> view the image

The following screen shot shows that Oracle scanned 101GB in 466 seconds—223 MB/s scanning throughput. I forgot to mention, this is a DL585 with only 2 paths to storage. Before some slight reconfiguration I had to do I had 3 paths to storage where I was seeing 329MB/s—or about 97% linear scalability when considering the maximum payload on GbE is on the order of 114MB/s for this sort of workload.

NFS Overhead? Cheating is Naughty!
The following screen shot shows vmstat output taken during the full table scanning. It shows that the Kernel mode processor utilization when Oracle uses Direct I/O to scan NFS files falls consistently in range of 22%. That is not entirely NFS overhead by any means either.
Of course Oracle doesn’t know if its I/O is truly physical since there could be OS buffering. The screen shot also shows the memory usage on the server. There was 31 of 32GB free which means I wasn’t scanning a 25GB table that was cached in the OS page cache. This was real I/O going over a real wire.

For more information I recommend:
This paper about Scalable Fault Tolerant NAS and the NFS-related postings on my blog.
There is no measurement for who does Small and Medium Business the best. I’ve always said that it is impossible to benchmark manageability. But, hey, Oracle always kills ‘em on the high end—as 4 Million+ TpmC will attest.
SMB
I’ve been watching for what Oracle will do in 2007, and beyond, to attack the SMB market. I take this press release as great news that Oracle is focusing on the SMB space. I firmly believe that the repricing of Standard Edition that allows up to 4 sockets—as opposed to 4 cores—combined with the flexibility one has for storage adoption with Oracle will be a winning combination. Remember, Oracle is the only database out there that enables you to deploy in the manner that makes sense for you be it FCP, iSCSI or NFS (NAS). And yes, Oracle11g does take that value proposition further.
Buy High, Sell Low and Make Up For It in Volume
Why did I sell my Oracle stock at $14.40?
What Does This Have to do with Storage?
SMB doesn’t exactly lend itself to Fibre Channel SANs. That bodes well for me since I’m in HP’s StorageWorks NAS division.
For just short of six years I’ve worked with a small group of people at a software startup (PolyServe) that was just bought out by HP. Today I was handed my ID badge—the first time I’ve worn one in 6 years. So, how does that phrase go?
Badges!? We ain’t got no badges. We don’t need no badges! I don’t have to show you any stinking badges! – Alfonso Bedoya
Times, they are a changin’…
In my post about RAC on Loosely-Coupled Clusters I discussed how strange it is to me that RAC is a shared disk architecture yet RAC deployments are shared-nothing for everything except the database. I mentioned the concept of Shared Applications Tier as well. Arnoud Roth has a post about shared APPL_TOP on the AMIS Technology Blog that I recommend you investigate. It seems there are some gaps in the shared APPL_TOP methodology that I was unaware of. There are a lot of folks doing shared APPL_TOP so perhaps they were all simply willing to work through these issues. They are issues nonetheless and do warrant consideration.
The problem with blogging is there is no way to clearly write something tongue-in-cheek. No facial expressions, no smirking, no hand waving—just plain old black and white. That aside, I can’t resist posting a follow-up to a post on StorageMojo about ZFS performance. I’m not taking a swipe at StorageMojo because it is one of my favorite blogs. However, every now and again third party perspective is a healthy thing. The topic at hand is this post about ZFS performance which is a digest of this post on digitalbadger.net. The original post starts with:
I have seen many benchmarks indicating that for general usage, ZFS should be at least as fast if not faster than UFS (directio not withstanding)[…]
Right off the bat I was scratching my head. I have experience with direct I/O dating back to 1991 and have some direct I/O related posts here. I was trying to figure out what the phrase “directio not withstanding” was supposed to mean. The only performance boost direct I/O can possibly yield is due to the elimination of the write-ordering locks generally imposed by POSIX and the double-buffering/memcopys overhead associated with the DMA into the page cache—and subsequent copy into the user address space buffer. So for a read-intensive benchmark, about the only thing one should expect is less processor overhead, not increased throughput.
Anyway, the post continues:
To give a little background : I have been experiencing really bad throughput on our 3510-based SAN. The hosts are X4100s, 12Gb RAM, 2x dual core 2.6Ghz opterons and Solaris 10 11/06. They are each connected to a 3510FC dual-controller array via a dual-port HBA and 2 Brocade SW200e switches, using MxPIO. All fabric is at 2Gb/s […]
OK, the 4100 is a 2-way Opteron 2000 server which, being a lot like an HP Proliant DL385, should have no problem consuming all the data the 2 x 2Gb FCP paths can deliver—roughly 400MB/s. If the post is about a UFS versus ZFS apples-apples comparison, both results should top out at the maximum theoretical throughput of 2x2Gb FCP. The post continues:
On average, I was seeing some pretty average to poor rates on the non-ZFS volumes depending on how they were configured, on average I was seeing 65MB/s write performance and around 450MB/s read on the SAN using a single drive LUN.
I’d be plenty happy with that 450MB/s given that configuration. The post insinuates this is direct I/O so getting 450MB/s out of 2x2Gb FCP should be the end of the contest. Further, getting 65MB/s written to a single drive LUN is quite snappy! What is left to benchmark? It seems UFS cranks the SAN at full bandwidth.
The post continues:
I then tried ZFS, and immediately started seeing a crazy rate of around 1GB/s read AND write, peaking at close to 2GB/s. Given that this was round 2 to 4 times the capacity of the fabric, it was clear something was going awry.
Hmmm…Opterons with HT 2.0 attaining peaks of 2GB/s write throughput via 2x2Gb FCP? There is nothing awry about this, it is simply not writing the data to the storage.
This is a memory test. ZFS is caching, UFS is not.
The post continues:
Many thanks to Greg Menke and Tim Bradshaw on comp.unix.solaris for their help in unravelling this mystery!
What mystery? I’d recommend testing something that runs longer than 1 second (reading 512MB from memory on any Opteron system should take about .6 seconds. I’d recommend a dataset that is about 2 fold larger than physical memory.
How Does ZFS and UFS Compare to Other Filesystems?
Let’s take a look at an equivalent test running on the HP Cluster Gateway internal filesystem (the former PolyServe PSFS). The following is a screen shot of a dd(1) test using real Oracle datafiles on a Proliant DL585. The first test executes a single thread of dd(1) reading the first 512MB of one of the files using 1M read requests. The throughput is 815MB/s. Next, I ran 2 concurrent dd(1) processes each chomping the first 512MB out of two different Oracle datafiles using 1MB read requests. In the concurrent case, the throughput was 1.46GB/s.
NOTE: You may have to right click->view the image.

But wait, in order to prove the vast superiority of the HP Cluster Gateway filesystem over ZFS using similar hardware, I fired off 6 concurrent dd(1) processes each reading the first 512MB out of six different files. Here I measured 2.9GB/s!

I really should read The Register more regularly. If I had I wouldn’t have been surprised to see today’s news about HP’s entry into the BI “appliance” space with Neoview Enterprise Data Warehouse as reported by MercuryNews.com and others. Inside there is Tandem NonStop technology running on Itanium-based server.
The press is touting this as an anti-Teradata play, but it seems to me as though it would also rival Neteeza since you can start with a 16 processor configuration and scale up.
What Does This Have to Do With Oracle?
That is always the question on my blog. The answer? Well, Oracle is, um, let’s say very keen on BI as well. Something to ponder…
I just read a nice piece by Robin Harris over at one of my favorite blogs, storagemojo.com, about large sequential I/Os being the future focus of storage. I think he is absolutely correct. Let’s face it; there is only so much data that can take the old familiar row and column form that we Oracle folk spend so much time thinking about. As Robin points out, digitizing the analog world around us is going to be the lion’s share of what consumes space on those little round, brown spinning things. Actually, the future is now.
Drives for OLTP? Where?
They aren’t making drives for OLTP anymore. I’ve been harping on this for quite some time and Robin touched on it in his fresh blog entry so I’ll quote him:
Disk drives: rapidly growing capacity; slowly growing IOPS. Small I/Os are costly. Big sequential I/Os are cheap. Databases have long used techniques to turn small I/Os into larger ones.
He is right. In fact, I blogged recently about DBWR multiblock writes. That is one example of optimizing to perform fewer, larger I/Os. However, there is a limit to how many such optimizations there are to be found in the traditional OLTP I/O profile. More to the point, hard drive manufacturers are not focused on getting us our random 4KB read or write in, say, 8ms or whatever we deem appropriate. OLTP is just not “sexy.” Instead, drive manufacturers are working out how to get large volumes of data crammed onto as few platters as possible. After all, they make money on capacity, not IOPS.
Did Oracle Get The Memo? Where is That Unstructured Data?
Many of you can recall the Relational, OODB and Object Relational wars of the 1990s. That not-so-bloody war left behind a lot of companies that closely resemble dried bones at this point. After all, Oracle had the relational model well under control and there wasn’t a whole lot of user-generated content in those days—the world was all about rows and columns. Over the last 7-10 years or so, folks have been using Oracle procedures to integrate unstructured data into their applications. That is, store the rows and columns in the database and call out to the filesystem for unstructured data such as photos, audio clips, and so on. You don’t think Oracle is going to give up on owning all that unstructured data do you?
The Gag Order
Oracle has put a gag-order on partners where Oracle11g is concerned—as is their prerogative to do. However, that makes it difficult for me to tie Oracle11g into this thread. Well, last week at COLLABORATE ’07, Oracle executives stumped about some Oracle11g features, but none that I can tie in with this blog post—I’m so sad. Hold it, here I find an abstract of a presentation given by an Oracle employee back in February 2007. Conveniently for me, the title of the presentation was Oracle 11g Secure Files: Unifying files in the database—exactly the feature I wanted to tie in. Good, I still haven’t revealed any information about Oracle futures that hasn’t shown up elsewhere on the Web! Whew. The abstract sums up what the Secure Files feature is:
Unifying the storage of files and relational data in the database further allows you to easily and securely manage files alongside the relational data.
Let me interpret. What that means is that Oracle wants you to start stuffing unstructured data inside a database. That is what the Object guys wanted as well. Sure, with such content inside an Oracle database the I/Os will be large and sequential but the point I’m trying to make is that 11g Secure Files puts a cross-hair on folks like Isilon—the company Robin discussed in his blog entry. Isilon specializes in what Robin calls “big file apps.” Having Oracle’s cross-hairs on you is not great fun. Ask one of the former OODB outfits. And lest we forget, Larry Ellison spent money throughout the 1990s to try to get nCUBE’s video on demand stuff working.
We’ve come full circle.
Disks, or Storage?
Today’s databases—Oracle included—make Operating System calls to access disks, or more succinctly, offsets in files. I’ll be blogging soon on Application Aware Storage which is an emerging technology that I find fascinating. Why just send your Operating System after offsets in files (disks) when you can ask the Storage for so much more?
Chalk this blog entry up under the “might help some poor Googler” someday column. This is a really weird Oracle installation error.
Lot’s of Clusters, Less Confusion
We have a lot of clusters here running Oracle on everything from Red Hat RHEL4 x86 and x86_64 to SuSE SLES9 x86 and x86_64. We also build clusters for certain test purposes such as analyzing how different kernels affect performance (thanks Carel-Jan), stability and so on. To keep things straight we generally build kernels and then name them with earmarks so that simple uname(1) output will tell us what the configuration is. For example, if we are running a test called “test3”, with the kernel build from the kernel-source-2.6.5-7.244.i586.rpm package, we might see the following when running the uname(1) command:
# uname -r
2.6.5-7.244-default-test3-244-0003-support
That is a long name for a kernel, but who should care? The manpage for the uname(2) call on Linux defines the arrays returned by the call as being unspecified in length:
The utsname struct is defined in <sys/utsname.h>:
struct utsname {
char sysname[];
char nodename[];
char release[];
char version[];
char machine[];
#ifdef _GNU_SOURCE
char domainname[];
#endif
};The length of the arrays in a struct utsname is unspecified; the fields are NUL-terminated.
[Blog Correction: Before updating this page I had erroneously pointed out that NUL was a misspelling. I was wrong. See the comment stream below.]
What Does This Have to Do With Oracle?
Installation! We were trying to install Oracle10g Release 2 version 10.2.0.1 on SuSE SLES9 U3 x86 and ran into the following:
$ ./runInstaller
*** glibc detected *** free(): invalid next size (fast): 0x0807aa80 ***
*** glibc detected *** free(): invalid next size (fast): 0x0807ab00 ***
*** glibc detected *** free(): invalid next size (fast): 0x0807ab28 ***
*** glibc detected *** free(): invalid next size (fast): 0x0807ab50 ***
[…much error text deleted…]
*** glibc detected *** free(): invalid next size (fast): 0x0807ab70 ***
*** glibc detected *** free(): invalid next size (fast): 0x0807ab98 ***
*** glibc detected *** free(): invalid next size (fast): 0x0807abc0 ***
*** glibc detected *** free(): invalid next size (normal): 0x0807ad88 ***
*** glibc detected *** free(): invalid next size (normal): 0x0807aef0 ***
./runInstaller: line 63: 11294 Segmentation fault $CMDDIR/install/.oui $* -formCluster
What? The runInstaller script executed .oui which in turn suffered a segmentation fault. After investigating .oui with ltrace(1) it became clear that .oui mallocs 30 bytes and then calls uname(2). In our case, the release[] array returned to .oui from the uname(2) library call was a bit large. Larger than 30 bytes for certain. In spite of the fact that the uname(2) manpage says the size of the release[] array is unspecified, .oui presumes it will fit in 30 bytes. The strcpy(P) call that followed tried to stuff the array containing our long kernel name(2.6.5-7.244-default-test3-244-0003-support) into a 30 byte space at 0x8075940. That resulted in a segmentation fault:
malloc(1024) = 0x8073118
malloc(1024) = 0x8073520
malloc(8192) = 0x8073928
malloc(8) = 0x8075930
malloc(30) = 0x8075940
uname(0xbfffba48 <unfinished …>
SYS_uname(0xbfffba48) = 0
<… uname resumed> ) = 0
strcpy(0x8075940, “2.6.5-7.244-default-test3-244-00″…) = 0x8075940
The Moral
Don’t use long kernel names on Oracle systems. And, oh, when a manpage says something is unspecified, that doesn’t necessarily mean 30.
I recently heard an Oracle Executive Vice President in Server Technologies development at Oracle cite RAC adoption at somewhere along the lines of 10,000 RAC deployments. He then balanced that number by stating there are on the order of 200,000 to 250,000 Oracle sites. Real Application Clusters has been shipping for just under 6 years now.
Real Application Clusters Adoption
There have been a lot of things standing in the way of RAC adoption. First, applications need to be tested to work with RAC. It took ages, for instance, to have even Oracle E-Biz suite and SAP certified on RAC. Second, if RAC doesn’t solve a problem for you, the odds are small you’ll deploy it. Third, RAC was introduced just prior to the major global IT spending downturn post-9/11, and RAC is not inexpensive. I’m sure there are third, fourth and many more reasons, some of which are centered more along techno-religious lines than purely technical.
I’ve been very involved with RAC since its initial release because my former company, PolyServe, helped some very large customers adopt the technology. All along I’ve been interested about any factors that hold back RAC adoption. In my personal experience, one significant factor is not really even a RAC issue. Instead, the difficulties in dealing with shared storage has historically put a bad taste in people’s collective mouths and technology like ASM only addresses part of the problem by handling the database—but none of the unstructured data necessary for a successful RAC deployment. That’s why I like NFS–but I digress.
A Poll
In this post on the oracle-l email list, a fellow OakTable Network member posted an invite to participate in a poll regarding Real Application Clusters. It only has a few questions in order to garner as much participation as possible. I do wish, however, it would ask one very important question:
Why aren’t you using RAC.
I encourage all of you RAC folks to participate in the poll here: A Poll About RAC. Let’s get as much valuable information out of this as possible. If you have a minute, maybe you non-RAC folks can submit a comment about why you don’t use RAC.
At the top of the Poll webpage you can click to get the current results.
This is part 6 in a series about Oracle on Opteron-based NUMA servers running Linux. The list of prior installments can be found through my index of NUMA-related posts.
In part 5 of the series I discussed using Opteron-based servers with NUMA features disabled in the BIOS. Running an Opteron server (e.g., HP Proliant DL585) in this fashion is sometimes called SUMA (Sufficiently Uniform Memory Access) or SUMO (Sufficiently Uniform Memory Organization). At the risk of being controversial, I pointed out that in the Oracle Validated Configuration listing for Proliant, the recommendation is given to configure Opteron-based servers as SUMO/SUMA. In my experience, most folks do not change the BIOS and are therefore running a NUMA system since that is the default. However, if steps are taken to disable NUMA on an Opteron system, there are subtleties that warrant deeper understanding. How subtle are the subtleties? That question is the main theme of this blog series.
Memory Latencies with SUMA/SUMO vs NUMA
In part 5 of the series, I used the SLB memory latency workload to show how memory writes differ in NUMA versus SUMA/SUMO. I wrote:
Writing memory on the SUMA configuration in the 8 concurrent memhammer case demonstrated latencies on order of 156ns but dropped 38% to 97ns by switching to NUMA and using the Linux 2.6 NUMA API.
But What About Oracle?
What is the cost of running Oracle on SUMA? The simple answer is, it depends. More architectural background is needed before I go into that.
SUMA, NUMA and CYCLOPS
OK, so SUMA is what you get when you tweak a Proliant Opteron-based server so that memory is interleaved at the low level. Accompanying this with the setting of numa=off in the grub.conf file gets you a completely non-NUMA setup.
Cyclops
NUMA enabled in the BIOS, however, is the default. If the Oracle ports to Linux were NUMA-aware, that would be just fine. However, if the server isn’t configured as a SUMA and you boot Oracle without any consideration for the fact that you are on a NUMA system, you get what I call Cyclops. Let’s take a look at what I mean.
In the following screen shot I have booted an Oracle10g SGA of 7584MB on my Proliant DL585. The system is configured with 32GB physical memory which is, of course, 4 banks of 8GB each attached to one of the 4 dual-core Opterons (nodes). Before booting this SGA, I had between roughly 7.6GB and 7.7GB free memory on each of the memory banks. In the following figure it’s clear that after booting this 7584MB SGA I am left with all but 116MB of memory consumed from node 0 (socket 0)—Cyclops!
NOTE: You may need to right click->view the image

Right, so really bad things can happen if processes that are memory-resident on node 0 try to allocate more memory. In the 2.4 Kernel timeframe Red Hat points out such ill affect as OOM process termination in this web page. I haven’t spent much time researching how 2.6 responds to it because the point of this blog entry to not get into such a situation.
Let’s consider what things are like on a Cyclops even if there are no process or memory allocation failures. Let’s say, for instance, there is a listener with soft node affinity to node 2. All the sessions it forks off will have node affinity to node 2 where they will be granted pages for their kernel structures, page tables, stack, heap and so on. However, the entire SGA is remote memory since as you can see all the memory for the SGA was allocated from node 0. That is, um, not good.
Hugepages Are More Attractive Than Cyclops
Cyclops pops up its ugly single-eyed head only when you are running NUMA (not SUMA/SOMA) and fail to allocate/use hugepages. Whether you allocate hugepages off the grub boot line or out of sysctl.conf, memory for hugepages is allocated in a distributed fashion from the varying memory banks. Did I say round-robin? No. Because I don’t yet know whether it is round-robin or segmented. I have to leave something to blog about in the future.
The following is a screen shot of a session where I allocated 3800 2MB hugepages after the system was booted by echoing that value into /proc/sys/vm/nr_hugepages. Notice that unlike Cyclops, the pages are allocated for Oracle’s future use in a more distributed fashion from the various memory banks. I then booted Oracle. No Cyclops here.
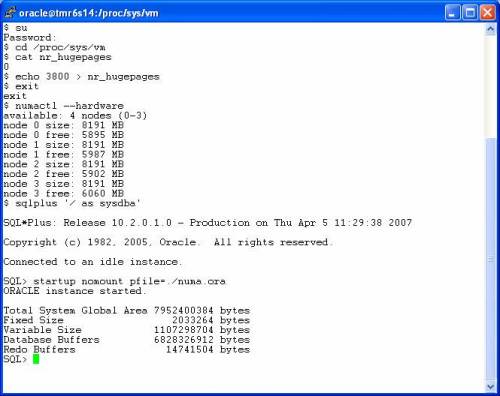
Interleaving NUMA Memory Allocation
The numactl(8) command supports the notion of pushing memory allocation preferences down to its children. Until such time as the Linux port of Oracle is NUMA-aware internally—as was done in the Sequent DYNIX/ptx, SGI, DG, and to a lesser degree the Solaris Oracle10g port with MPO—the best hopes for efficient memory usage on a commodity NUMA system is to interleave the placement of shared memory via numactl(8). With the SGA allocated in this fashion on a 4-socket NUMA system, Oracle’s memory accesses for the variable and buffer pool components will have locality of up to 25%–generally speaking. Yes, I’m sure some session could go crazy with logical reads of 2 buffers 20,000 times per second or some pathological situation, but I am trying to cover the topic in more general terms. You might wonder how this differs from SUMA/SOMA though.
With SUMA, all memory is interleaved. That means even the NUMA-aware Linux 2.6 kernel cannot exploit the hardware architecture by allocating structures with respect to the memory hierarchies. That is a pure waste. Moreover, with SUMA, 100% of your Oracle memory accesses will hit interleaved memory. That includes PGA. In contrast, properly allocated NUMA-interleaved hugepages results in fairness in the SGA placement, but allocation in the PGA (heap) and stack for the sessions are 100% local memory! That is a good thing. In the following screen shot I coupled numactl(8) memory interleaving with hugepages.
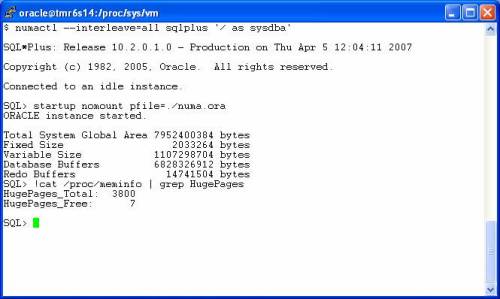
Validated Oracle Configuration
As I pointed out, this Oracle Validated Configuration listing for Proliant recommends turning off NUMA. Now that I’m an HP employee, I’ll have to pursue that a bit because I don’t agree with it at all. You’ll see why when I post my performance measurements contrasting NUMA (with interleave hugepages) to SUMA/SOMA. Look at that Validated Configuration web page closely and you’ll see a recommendation to allow Oracle to use hugepages by tuning /etc/security/limits.conf, but neither allocation of hugepages from the grub boot line nor via the sysctl.conf file!
Could it be that the recommendations in this Validated Configuration were a knee-jerk reaction to Cyclops? I’m not much of a betting man, but I’d wager $5.00 that was the case. Like I said, I’m in HP now…I’ll have to see what all that was about.
Up Next
In my next installment, I will provide Oracle measurements contrasting SUMA and NUMA. I know I’ve said this would be the installment with Oracle performance numbers, but I had to lay too much ground work in this post. The mind can only absorb what the seat can endure.
Patent Infringement
For all you folks that hate the concept of software patents, here’s a good one. When my Sequent colleagues and I were working out the OS-requirements to support our NUMA-optimizations of the Oracle 8 port to Sequent’s NUMA-Q system, we knew early on we’d need a very rich set of enhancements to shmget() for memory region placement. So we specified the requirements to our OS developers. Lo and behold U.S. Patent 6,505,286 plopped out. So, for extra credit, can someone explain to me how the Linux 2.6 libnuma call numa_alloc_onnode() (described here) is not in complete violation of that patent? Hmmm…
Now for a real taste of NUMA-Oracle history, read the following: Sequent_NUMA_Oracle8i

Click It


Recent Comments