This blog entry is part five in a series. Please visit here for links to the previous installments.
Opteron-Based Servers are NUMA Systems
Or are they? It depends on how you boot them. For instance, I have 2 HP DL585 servers clustered with the PolyServe Database Utility for Oracle RAC. I booted one of the servers as a non-NUMA by tweaking the BIOS so that memory was interleaved on a 4KB basis. This is a memory model HP calls Sufficiently Uniform Memory Access (SUMA) as stated in this DL585 Technology Brief (pg. 6):
Node interleaving (SUMA) breaks memory into 4-KB addressable entities. Addressing starts with address 0 on node 0 and sequentially assigns through address 4095 to node 0, addresses 4096 through 8191 to node 1, addresses 8192 through 12287 to node 3, and addresses 12888
Booting in this fashion essentially turns an HP DL585 into a “flat-memory” SMP—or a SUMA in HP parlance. There seems to be conflicting monikers for using Opteron SMPs in this mode. IBM has a Redbook that covers the varying NUMA offerings in their System x portfolio. The abstract for this Redbook states:
The AMD Opteron implementation is called Sufficiently Uniform Memory Organization (SUMO) and is also a NUMA architecture. In the case of the Opteron, each processor has its own “local” memory with low latency. Every CPU can also access the memory of any other CPU in the system but at longer latency.
Whether it is SUMA or SUMO, the concept is cool, but a bit foreign to me given my NUMA background. The NUMA systems I worked on in the 90s consisted of distinct, separate small systems—each with their own memory and I/O cards, power supplies and so on. They were coupled into a single shared memory image with specialized hardware inserted into the system bus of each little system. These cards were linked together and the whole package was a cache coherent SMP (ccNUMA).
Is SUMA Recommended For Oracle?
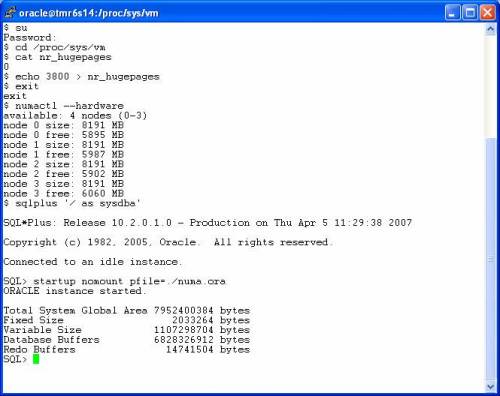
Since the HP DL585 can be SUMA/SUMO, I thought I’d give it a test. But first I did a little research to see how most folks use these in the field. I know from the BIOS on my system that you actually get a warning and have to override it when setting up interleaved memory (SUMA). I also noticed that in one of HP’s Oracle Validated Configurations, the following statement is made:
Settings in the server BIOS adjusted to allow memory/node interleaving to work better with the ‘numa=off’ boot option
and:
Boot options
elevator=deadline numa=off
I found this to be strange, but I don’t yet fully understand why that recommendation is made. Why did they perform this validation with SUMA? When running a 4-socket Opteron system in SUMA mode, only 25% of all memory accesses will be to local memory. When I say all, I mean all—both user and kernel mode. The Linux 2.6 kernel is NUMA-aware so is seems like a waste to transform a NUMA system into a SUMA system? How can boiling down a NUMA system with interleaving (SUMA) possibly be optimal for Oracle? I will blog about this more as this series continues.
Is the x86_64 Linux Oracle Port NUMA Aware?
No, sorry, it is not. I might as well just come out and say it.
The NUMA API for Linux is very rudimentary compared to the boutique features in legacy NUMA systems like Sequent DYNIX/ptx and SGI IRIX, but it does support memory and process placement. I’ll blog later about this things it is missing that a NUMA aware Oracle port would require.
The Linux 2.6 kernel is NUMA aware, but what is there for applicaitons? The NUMA API which is implemented in the library called libnuma.so. But you don’t have to code to the API to effect NUMA awareness. The major 2.6 Linux kernel distributions (RHEL4 and SLES) ship with a command that uses the NUMA API in ways I’ll show later in this blog entry. The command is numactl(8) and it dynamically links to the NUMA API library (emphasis added by me):
$ uname -a
Linux tmr6s13 2.6.9-34.ELsmp #1 SMP Fri Feb 24 16:56:28 EST 2006 x86_64 x86_64 x86_64 GNU/Linux
$ type numactl
numactl is hashed (/usr/bin/numactl)
$ ldd /usr/bin/numactl
libnuma.so.1 => /usr/lib64/libnuma.so.1 (0x0000003ba3200000)
libc.so.6 => /lib64/tls/libc.so.6 (0x0000003ba2f00000)
/lib64/ld-linux-x86-64.so.2 (0x0000003ba2d00000)
Whereas the numactl(8) command links with libnuma.so, Oracle does not:
$ type oracle
oracle is /u01/app/oracle/product/10.2.0/db_1/bin/oracle
$ ldd /u01/app/oracle/product/10.2.0/db_1/bin/oracle
libskgxp10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libskgxp10.so (0x0000002a95557000)
libhasgen10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libhasgen10.so (0x0000002a9565a000)
libskgxn2.so => /u01/app/oracle/product/10.2.0/db_1/lib/libskgxn2.so (0x0000002a9584d000)
libocr10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libocr10.so (0x0000002a9594f000)
libocrb10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libocrb10.so (0x0000002a95ab4000)
libocrutl10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libocrutl10.so (0x0000002a95bf0000)
libjox10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libjox10.so (0x0000002a95d65000)
libclsra10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libclsra10.so (0x0000002a96830000)
libdbcfg10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libdbcfg10.so (0x0000002a96938000)
libnnz10.so => /u01/app/oracle/product/10.2.0/db_1/lib/libnnz10.so (0x0000002a96a55000)
libaio.so.1 => /usr/lib64/libaio.so.1 (0x0000002a96f15000)
libdl.so.2 => /lib64/libdl.so.2 (0x0000003ba3200000)
libm.so.6 => /lib64/tls/libm.so.6 (0x0000003ba3400000)
libpthread.so.0 => /lib64/tls/libpthread.so.0 (0x0000003ba3800000)
libnsl.so.1 => /lib64/libnsl.so.1 (0x0000003ba7300000)
libc.so.6 => /lib64/tls/libc.so.6 (0x0000003ba2f00000)
/lib64/ld-linux-x86-64.so.2 (0x0000003ba2d00000)
No Big Deal, Right?
This NUMA stuff must just be a farce then, right? Let’s dig in. First, I’ll use the SLB (http://oaktable.net/getFile/148). Later I’ll move on to what fellow OakTable Network member Anjo Kolk and I refer to as the Jonathan Lewis Oracle Computing Index. The JL Oracle Computing Index is yet another microbenchmark that is very easy to run and compare memory throughput from one server to another using an Oracle workload. I’ll use this next to blog about NUMA effects/affects on a running instance of Oracle. After that I’ll move on to more robust Oracle OLTP and DSS workloads. But first, more SLB.
The SLB on SUMA/SOMA
First, let’s use the numactl(8) command to see what this DL585 looks like. Is it NUMA or SUMA?
$ uname -a
Linux tmr6s13 2.6.9-34.ELsmp #1 SMP Fri Feb 24 16:56:28 EST 2006 x86_64 x86_64 x86_64 GNU/Linux
$ numactl –hardware
available: 1 nodes (0-0)
node 0 size: 32767 MB
node 0 free: 30640 MB
OK, this is a single node NUMA—or SUMA since it was booted with memory interleaving on. If it wasn’t for that boot option the command would report memory for all 4 “nodes” (nodes are sockets in the Opteron NUMA world). So, I set up a series of SLB tests as follows:
$ cat example1
echo “One thread”
./cpu_bind $$ 7
./create_sem
./memhammer 262144 6000 &
./trigger
wait
echo “Two Threads, same core”
./cpu_bind $$ 7
./create_sem
./memhammer 262144 6000 &
./cpu_bind $$ 6
echo “One thread”
./cpu_bind $$ 7
./create_sem
./memhammer 262144 6000 &
./trigger
wait
echo “Two threads, same socket”
./cpu_bind $$ 7
./create_sem
./memhammer 262144 6000 &
./cpu_bind $$ 6
./memhammer 262144 6000 &
./trigger
wait
echo “Two threads, different sockets”
./cpu_bind $$ 7
./create_sem
./memhammer 262144 6000 &
./cpu_bind $$ 5
./memhammer 262144 6000 &
./trigger
wait
echo “4 threads, 4 sockets”
./cpu_bind $$ 7
./create_sem
./memhammer 262144 6000 &
./cpu_bind $$ 5
./memhammer 262144 6000 &
./cpu_bind $$ 3
./memhammer 262144 6000 &
./cpu_bind $$ 1
./memhammer 262144 6000 &
./trigger
wait
echo “8 threads, 4 sockets”
./cpu_bind $$ 7
./create_sem
./memhammer 262144 6000 &
./memhammer 262144 6000 &
./cpu_bind $$ 5
./memhammer 262144 6000 &
./memhammer 262144 6000 &
./cpu_bind $$ 3
./memhammer 262144 6000 &
./memhammer 262144 6000 &
./cpu_bind $$ 1
./memhammer 262144 6000 &
./memhammer 262144 6000 &
./trigger
wait
And now the measurements:
$ sh ./example1
One thread
Total ops 1572864000 Avg nsec/op 71.5 gettimeofday usec 112433955 TPUT ops/sec 13989225.9
Two threads, same socket
Total ops 1572864000 Avg nsec/op 73.4 gettimeofday usec 115428009 TPUT ops/sec 13626363.4
Total ops 1572864000 Avg nsec/op 74.2 gettimeofday usec 116740373 TPUT ops/sec 13473179.5
Two threads, different sockets
Total ops 1572864000 Avg nsec/op 73.0 gettimeofday usec 114759102 TPUT ops/sec 13705788.7
Total ops 1572864000 Avg nsec/op 73.0 gettimeofday usec 114853095 TPUT ops/sec 13694572.2
4 threads, 4 sockets
Total ops 1572864000 Avg nsec/op 78.1 gettimeofday usec 122879394 TPUT ops/sec 12800063.1
Total ops 1572864000 Avg nsec/op 78.1 gettimeofday usec 122820373 TPUT ops/sec 12806214.2
Total ops 1572864000 Avg nsec/op 78.2 gettimeofday usec 123016921 TPUT ops/sec 12785753.3
Total ops 1572864000 Avg nsec/op 78.5 gettimeofday usec 123527864 TPUT ops/sec 12732868.1
8 threads, 4 sockets
Total ops 1572864000 Avg nsec/op 156.3 gettimeofday usec 245773200 TPUT ops/sec 6399656.3
Total ops 1572864000 Avg nsec/op 156.3 gettimeofday usec 245848989 TPUT ops/sec 6397683.4
Total ops 1572864000 Avg nsec/op 156.4 gettimeofday usec 245941009 TPUT ops/sec 6395289.7
Total ops 1572864000 Avg nsec/op 156.4 gettimeofday usec 246000176 TPUT ops/sec 6393751.5
Total ops 1572864000 Avg nsec/op 156.6 gettimeofday usec 246262366 TPUT ops/sec 6386944.2
Total ops 1572864000 Avg nsec/op 156.5 gettimeofday usec 246221624 TPUT ops/sec 6388001.1
Total ops 1572864000 Avg nsec/op 156.7 gettimeofday usec 246402465 TPUT ops/sec 6383312.8
Total ops 1572864000 Avg nsec/op 156.8 gettimeofday usec 246594031 TPUT ops/sec 6378353.9
SUMA baselines at 71.5ns average write operation and tops out at about 156ns with 8 concurrent threads of SLB execution (one per core). Let’s see what SLB on NUMA does.
SLB on NUMA
First, let’s get an idea what the memory layout is like:
$ uname -a
Linux tmr6s14 2.6.9-34.ELsmp #1 SMP Fri Feb 24 16:56:28 EST 2006 x86_64 x86_64 x86_64 GNU/Linux
$ numactl –hardware
available: 4 nodes (0-3)
node 0 size: 8191 MB
node 0 free: 5526 MB
node 1 size: 8191 MB
node 1 free: 6973 MB
node 2 size: 8191 MB
node 2 free: 7841 MB
node 3 size: 8191 MB
node 3 free: 7707 MB
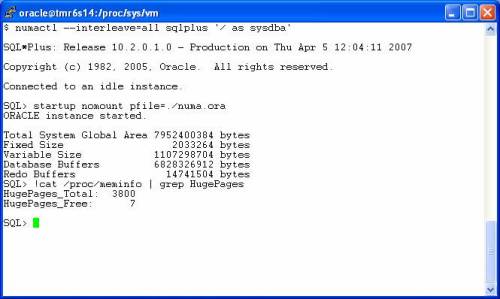
OK, this means that there is approximately 5.5GB, 6.9GB, 7.8GB and 7.7GB of free memory on “nodes” 0, 1, 2 and 3 respectively. Why is the first node (node 0) lop-sided? I’ll tell you in the next blog entry. Let’s run some SLB. First, I’ll use numactl(8) to invoke memhammer with the directive that forces allocation of memory on a node-local basis. The first test is one memhammer process per socket:
$ cat ./membind_example.4
./create_sem
numactl –membind 3 –cpubind 3 ./memhammer 262144 6000 &
numactl –membind 2 –cpubind 2 ./memhammer 262144 6000 &
numactl –membind 1 –cpubind 1 ./memhammer 262144 6000 &
numactl –membind 0 –cpubind 0 ./memhammer 262144 6000 &
./trigger
wait
$ bash ./membind_example.4
Total ops 1572864000 Avg nsec/op 67.5 gettimeofday usec 106113673 TPUT ops/sec 14822444.2
Total ops 1572864000 Avg nsec/op 67.6 gettimeofday usec 106332351 TPUT ops/sec 14791961.1
Total ops 1572864000 Avg nsec/op 68.4 gettimeofday usec 107661537 TPUT ops/sec 14609340.0
Total ops 1572864000 Avg nsec/op 69.7 gettimeofday usec 109591100 TPUT ops/sec 14352114.4
This test is the same as the one above called “4 threads, 4 sockets” performed on the SOMA configuration where the latencies were 78ns. Switching from SOMA to NUMA and executing with NUMA placement brought the latencies down 13% to an average of 68ns. Interesting. Moreover, this test with 4 concurrent memhammer processes actually demonstrates better latencies than the single process average on SUMA which was 72ns. That comparison alone is quite interesting because it makes the point quite clear that SUMA in a 4-socket system is a 75% remote memory configuration—even for a single process like memhammer.
The next test was 2 memhammer processes per socket:
$ more membind_example.8
./create_sem
numactl –membind 3 –cpubind 3 ./memhammer 262144 6000 &
numactl –membind 3 –cpubind 3 ./memhammer 262144 6000 &
numactl –membind 2 –cpubind 2 ./memhammer 262144 6000 &
numactl –membind 2 –cpubind 2 ./memhammer 262144 6000 &
numactl –membind 1 –cpubind 1 ./memhammer 262144 6000 &
numactl –membind 1 –cpubind 1 ./memhammer 262144 6000 &
numactl –membind 0 –cpubind 0 ./memhammer 262144 6000 &
numactl –membind 0 –cpubind 0 ./memhammer 262144 6000 &
./trigger
wait
$ sh ./membind_example.8
Total ops 1572864000 Avg nsec/op 95.8 gettimeofday usec 150674658 TPUT ops/sec 10438809.2
Total ops 1572864000 Avg nsec/op 96.5 gettimeofday usec 151843720 TPUT ops/sec 10358439.6
Total ops 1572864000 Avg nsec/op 96.9 gettimeofday usec 152368004 TPUT ops/sec 10322797.2
Total ops 1572864000 Avg nsec/op 96.9 gettimeofday usec 152433799 TPUT ops/sec 10318341.5
Total ops 1572864000 Avg nsec/op 96.9 gettimeofday usec 152436721 TPUT ops/sec 10318143.7
Total ops 1572864000 Avg nsec/op 97.0 gettimeofday usec 152635902 TPUT ops/sec 10304679.2
Total ops 1572864000 Avg nsec/op 97.2 gettimeofday usec 152819686 TPUT ops/sec 10292286.6
Total ops 1572864000 Avg nsec/op 97.6 gettimeofday usec 153494359 TPUT ops/sec 10247047.6
What’s that? Writing memory on the SUMA configuration in the 8 concurrent memhammer case demonstrated latencies on order of 156ns but dropped 38% to 97ns by switching to NUMA and using the Linux 2.6 NUMA API. No, of course an Oracle workload is not all random writes, but a system has to be able to handle the difficult aspects of a workload in order to offer good throughput. I won’t ask the rhetorical question of why Oracle is not NUMA aware in the x86_64 Linux ports until my next blog entry where the measurements will not be based on the SLB, but a real Oracle instance instead.
Déjà vu
Hold it. Didn’t the Dell PS1900 with a Clovertown Xeon quad-core E5320’s exhibit ~500ns latencies with only 4 concurrent threads of SLB execution (1 per core)? That was what was shown in this blog entry. Interesting.
I hope it is becoming clear why NUMA awareness is interesting. NUMA systems offer a great deal of potential incremental bandwidth when local memory is preferred over remote memory.
Next up—comparisons of SUMA versus NUMA with the Jonathan Lewis Computing Index and why all is not lost just because the 10gR2 x86_64 Linux port is not NUMA aware.






Recent Comments