This blog post is centered on All-Flash Array(AFA) technology. I mostly work with EMC XtremIO but the majority of my points will be relevant for any AFA. I’ll specifically call out an array that doesn’t fit any of the value propositions / methods I’m writing about in this post.
Oracle Automatic Storage Management (ASM) is a very good volume manager and since it is purpose-built for Oracle Database it is the most popular storage presentation model DBAs use today. That is not to say alternatives such as NFS (with optional Direct NFS) and simple non-clustered file systems are obsolete. Not at all. However, this post is about adding capacity to ASM disk groups in an all-flash storage environment.
Are You Adding Capacity or Adding I/O Performance?
One of the historical strengths of ASM is the fact that it supports adding a disk even though the disk group is more or less striped and mirrored (in the case of normal or high redundancy). After adding a disk to an ASM disk group there is a rebalancing of existing data to spread it out over all of the disks–including the newly-added disk(s). This was never possible with a host volume manager in, for example, RAID-10. The significant positive effect of an ASM rebalance is realized, first and foremost, in a mechanical storage environment. In short, adding a disk historically meant adding more read/write heads over your data, therefore, adding capacity meant adding IOPS capability (presuming no other bottlenecks in the plumbing).
The historical benefit of adding a disk was also seen at the host level. Adding a disk (or LUN) means adding a block device and, therefore, more I/O queues at the host level. More aggregate queue depth means more I/O can be “in-flight.”
With All-Flash Array technology, neither of these reasons for rebalance make it worth adding ASM disks when additional space is needed. I’ll just come out and say it in a quotable form:
If you have All-Flash Array technology it is not necessary to treat it precisely the same way you did mechanical storage.
It Isn’t Even A Disk
In the All-Flash Array world the object you are adding as an ASM disk is not a disk at all and it certainly has nothing like arms, heads and actuators that need to scale out in order to handle more IOPS. All-Flash Arrays allows you to create a volume of a particular size. That’s it. You don’t toil with particulars such as what the object “looks like” inside the array. When you allocate a volume from an All-Flash Array you don’t have to think about which controller within the array, which disk shelf, nor what internal RAID attributes are involved. An AFA volume is a thing of a particular size. That’s it. These words are 100% true about EMC XtremIO and, to the best of my knowledge, most competitors offerings are this was as well. The notable exception is the HP 3PAR StoreServ 7450 All-Flash Array which burdens administrators with details more suited to mechanical storage as is clearly evident in the technical white paper available on the HP website (click here).
What About Aggregate Host I/O Queue Depth?
So, it’s true that adding a disk to an ASM disk group in the All-Flash Array world is not a way to make better use of the array–unlike an array built on mechanical storage. What about the host-level benefit of adding a block device and therefore increasing host aggregate I/O queue depth? As it turns out, I just blogged a rather in-depth series of posts on the matter. Please see the following posts where I aim to convince readers that you really do not need to assemble large numbers of block devices in order to get significant IOPS capacity on modern hosts attached to low-latency storage such as EMC XtremIO.
What’s It All Mean?
To summarize the current state of the art regarding adding disks to ASM disks groups:
- Adding disks to ASM disk groups is not necessary to improve All Flash Array “drive” utilization.
- Adding disks to ASM disk groups is not necessary to improve aggregate host I/O queue depth–unless your database instance demands huge IOPS–which it most likely doesn’t.
So why do so many–if not most–Oracle shops still do the old add-a-disk-when-I-need-space thing? Well, I’m inclined to say it’s because that’s how they’ve always done it. By saying that I am not denigrating anyone! After all, if that’s the way it’s always been done then there is a track record of success and in today’s chaotic IT world I have no qualms with doing some that is proven. But loading JES3 card decks into a card reader to fire off an IBM 370 job was proven and we don’t do much of that these days.
If doing something simpler has no ill effect, it’s probably worth consideration.
If You Need More Capacity, Um, Why Not Make Your Disk(s) Larger?
I brought that up in twitter recently and was met with a surprising amount of negative feedback. I understood the face value of the objections and that’s why I’m starting this section of the post with objection-handling. The objections all seemed to have revolved about the number of “changes” involved with resizing disks in an ASM disk group when more space is needed. That is, the consensus seemed to believe that resizing, say, 4 ASM disks accounts for more “changes” than adding a single disk to 4 existing disks. Actually, adding a disk makes more changes. Please read on.
Note: Please don’t forget that I’m writing about resizing disks in an All-Flash Array like EMC XtremIO or even competitive products in the same product space.
A Scenario
Consider, for example, an ASM disk group that is comprised of 4 LUNs mapped to 4 volumes in an All Flash Array like (like XtremIO). Let’s say the LUNs are each 128GB for a disk group capacity of 512GB (external redundancy of course). Let’s say further that the amount of space to be added is another 128GB–a 25% increase and that the existing space is nearly exhausted. The administrators can pick from the following options:
- Add a new 128GB disk (LUN). This involves a) creating the volume in the array and b) discovering the block device on the host and c) editing udev rules configuration files for the new device and c) adding the disk to ASM and, finally, d) performing a rebalance.
- Resize the existing 4 LUNs to 160GB each. This involves a) modifying 4 volumes in the array to increase their size and b) discovering the block device on the host and c) updating the run-time multipath metadata (runtime command, no config file changes) and d) executing the ASM alter diskgroup resize all command (merely updates ASM metadata).
Option #1 in the list makes a change in the array (adding a volume deducts from fixed object counts) and two Operating System changes (you are creating a block device and editing udev config files and–most importantly–ASM will perform significant physical I/O to redistribute the existing data to fan it out from 4 disks to 5 disks.
Option #2 in the list actually make no changes.
If doing something simpler has no ill effect, it’s probably worth consideration.
The Resizing Approach Really Involves No Changes?
How can I say resizing 4 volumes in an array constitutes no changes? OK, I admit I might be splitting hairs on this but bear with me. If you create a volume in an array you have a new object that has to be associated with the ASM disk group. This means everything from naming it to tagging it and so forth. Additionally, arrays do not have an infinite number of volumes available. Moreover, arrays like XtremIO support vast numbers of volumes and snapshots but if your ASM disk groups are comprised of large numbers of volumes it takes little time to exhaust even the huge supported limit of snapshots in a product like XtremIO. If you can take the leap of faith with me regarding the difference between creating a volume in an All-Flash Array versus increasing the size of a volume then the difference at the host and ASM level will only be icing on the cake.
The host in Option #2 truly undergoes no changes. None. In the case study below you’ll see that resizing block devices on modern Linux hosts is an operation that involves no changes. None.
But It’s Really All About The Disruption
If you add a disk to an ASM disk group you are making storage and host changes and you are disrupting operations due to the rebalancing. On the contrary the resize disks approach is clearly free of changes and is even more clearly free of disruption. Allow me to explain.
The Rebalance Is A Disruption–And More
The prime concern about adding disks should be the overhead of the rebalance operation. But so many DBAs say they can simply lower the rebalance power limit (throttle the rebalance to lessen its toll on other I/O activity).
If administrators wish to complete the rebalance operation as quickly as possible then the task is postponed for a maintenance window. Otherwise production I/O service times can suffer due to the aggressive nature of ASM disk rebalance I/O. On the other hand, some administrators add disks during production processing and simply set the ASM rebalance POWER level to the lowest value. This introduces significant risk. If an ASM disk is added to an ASM disk group in a space-full situation the only free space for new data being inserted is in the newly added disk. The effect this has on data distribution can be significant if the rebalance operation takes significant time while new data is being inserted.
In other words, with the add-disk method administrators are a) making changes in the array, making changes in the Operating System and physically rebalancing existing data and doing so in a maintenance window or with a low rebalance power limit and likely causing data placement skew.
The resize-disk approach makes no changes and causes no disruption and is nearly immediate. It is a task administrators can perform outside maintenance windows.
What If My Disks Cannot Be Resized Because They are Already Large?
An ASM disk in 11g can be 2TB and in 12c, 4PB. Now, of course, Linux block devices cannot be 4PB but that’s what Oracle documentation says they can (obviously theoretically) be. If you have an ASM disk group where all the disks have been resized to 2TB then you have to add a disk. What’s the trade off? We’ll, as the disks were being resized over time to 2TB you made no changes in the array nor the operating system and you never once suffered a rebalance operation. Sure, eventually a disk needed to be added but that is a much less disruptive evolution for a disk group.
Case Study
The following section of this blog post shows a case study of what’s involved when choosing to resize disks as opposed to constantly adding disks. The case study was, of course, conducted on XtremIO so the array-level information is specific to that array.
Every task necessary to resize ASM disks can be conducted without application interruption on modern Linux servers attached to XtremIO storage array. The following section shows an example of the tasks necessary to resize ASM disks in an XtremIO environment—without application interruption.
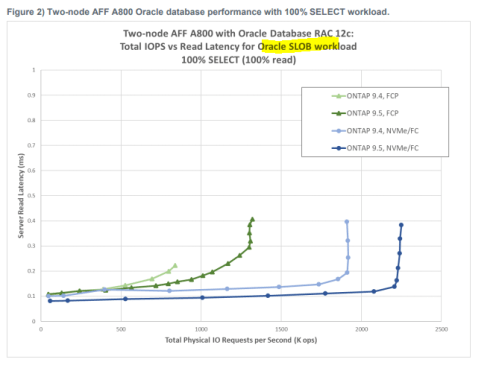
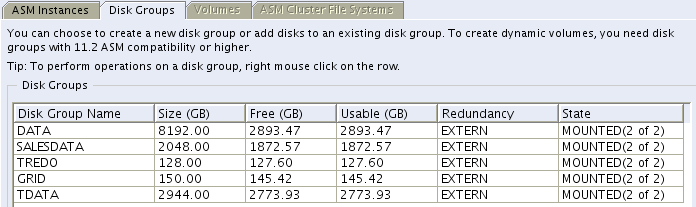
Figure 1 shows a screen shot of the ASM Configuration Assistant (ASMCA). In the example, SALESDATA is the disk group that will be resized from one terabyte to two terabytes.

Figure 1
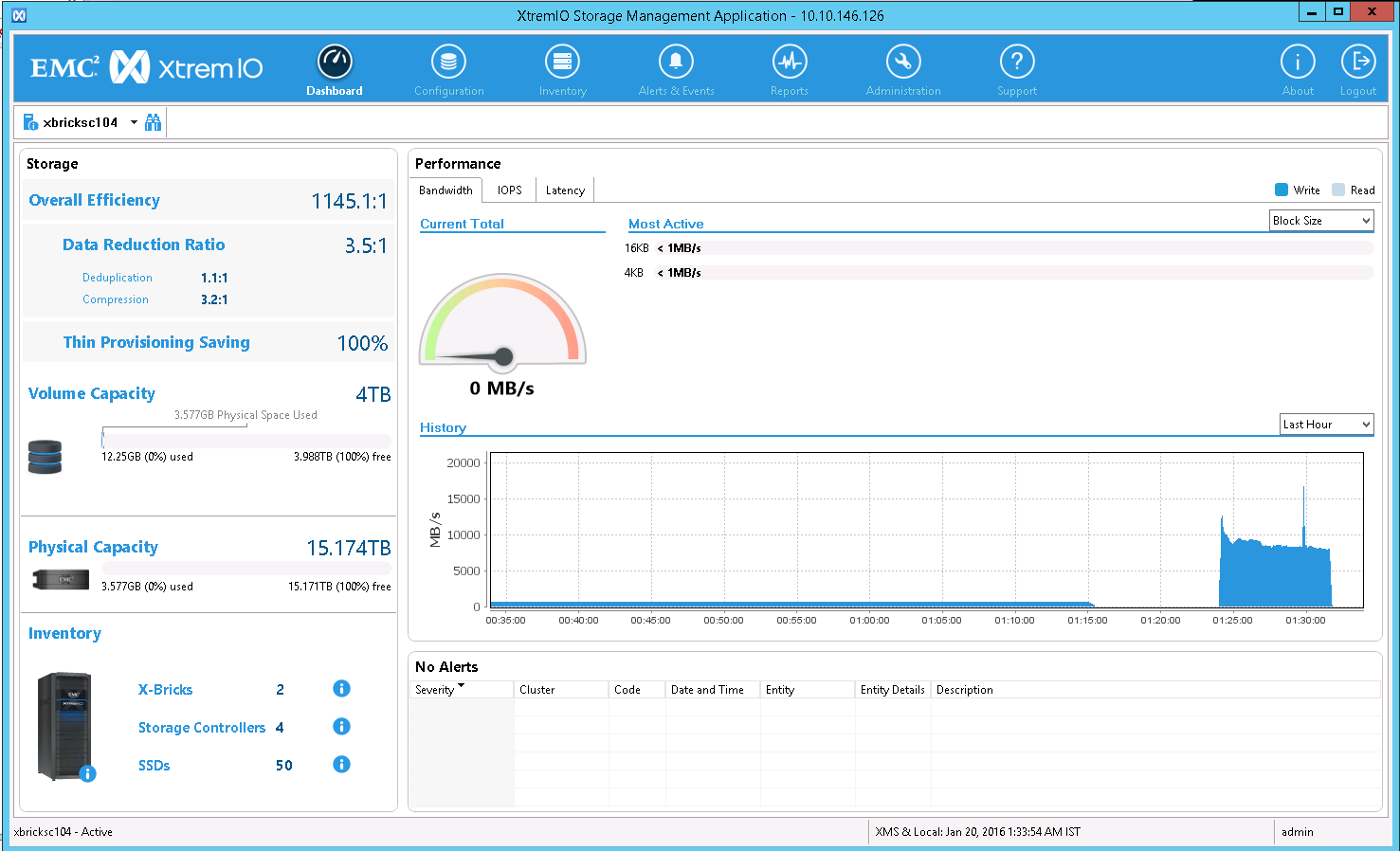
Figure 2 shows the XtremIO GUI with focus on the four volumes that comprise the SALESDATA disk group. Since all of the ASM disk space for SALESDATA has been allocated to tablespaces in the database, the Space in Use column shows that the volume space is entirely consumed.

Figure 2
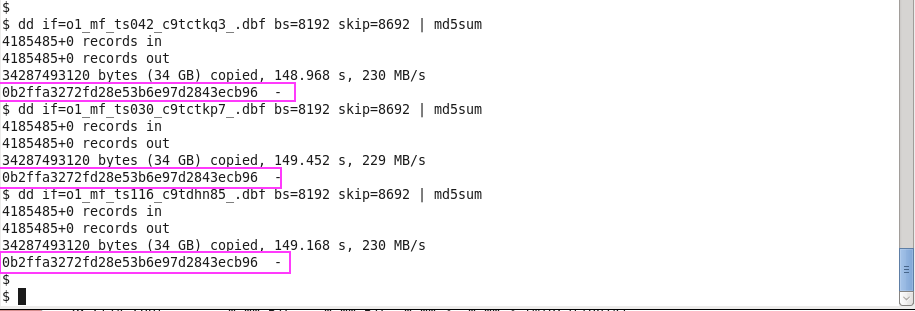
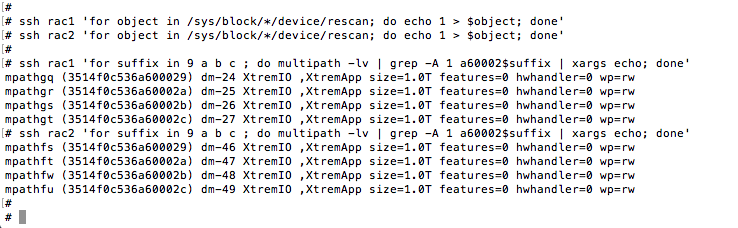
Figure 3 shows the simple, non-disruptive operating system commands needed to determine the multipath device name that corresponds to each XtremIO volume. This is a simple procedure. The NAA Identifier (see Figure 2) is used to query the Device Mapper metadata. As the Figure 3 shows, each LUN is 256GB and the corresponding multipath device for each LUN is reported in the left-most column of the xargs(1) output.

Figure 3
The next step in the resize procedure is to increase the size of the XtremIO volumes. Figure 4 shows the screen output just prior to resizing the fourth of four volumes from the original size of 256GB to the new size of 512GB.

Figure 4
Once the XtremIO volume resize operations are complete (these operations are immediate with XtremIO), the next step is to rescan SCSI busses on the host for any attribute changes to the underlying LUNs. As figure 5 shows, only a matter of seconds is required to rescan for changes. This, too, is non-disruptive.

Figure 5
Once the rescan has completed, the administrator can once again query the multipath devices to find that the LUNs are, in fact, recognized as having been resized as seen in Figure 6.

Figure 6
The final operating system level step is to use the multipathd(8) command to resize the multipath device (see Figure 7). This is non-disruptive as well.

Figure 7
As Figure 8 shows, the next step is to use the ALTER DISKGROUP command while attached to the ASM instance. The execution of this command is nearly immediate and, of course, non-disruptive. Most importantly, after this command completes the new capacity is available and no rebalance operation was required!

Figure 8
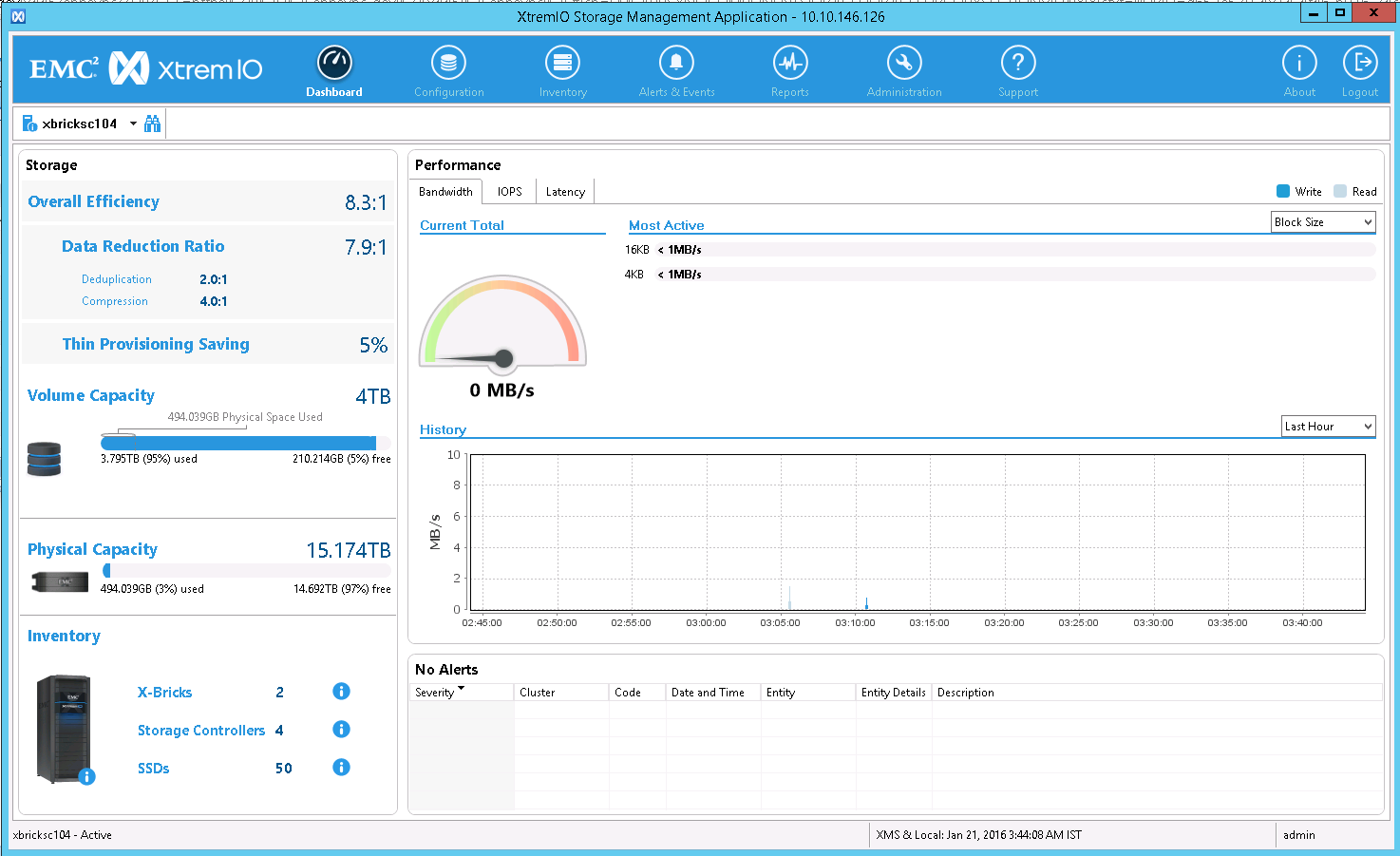
Finally, as Figure 9 shows, ASM Configuration Assistant will now show the new size of the disk group. In the example, the SALESDATA disk group has been resized from 1TB to 2TB in a matter of seconds—with no application interruption and no I/O impact from a rebalance operation.

Figure 9
Summary
If you have an All-Flash Array, like EMC XtremIO, take advantage of modern technology. Memories of constantly adding disks to ASM disk groups all over your datacenter can fade into vague memories–just like loading those JES3 decks into the card reader of your IBM 370. And, yes, I’ve written and loaded JES3 decks for an IBM 370 but I don’t feel compelled to do that sort of thing any more. Just like constantly adding disks to ASM disk groups some of the old ways are no longer the best ways.






















































{kind=link}
Recent Comments