I recently had some cycles on a freshly installed Dell EMC XtremIO Storage Array. I took this opportunity to prepare a blog entry about the never-ending topic of whether or not storage arrays are able to reduce physical data capacity through deduplication of blocks in Oracle Database.
Of Course There Is Duplicate Data In Oracle Datafiles
Before I continue, let me say something that may come as a surprise to you. Yes, Oracle Database has duplicate blocks in tablespaces! Yes, modern storage arrays can achieve astonishing data reduction rates through deduplication–even when the only data in the array is Oracle Database (whether ASM or file systems)!
XtremIO computes and displays global data reduction rate. This makes it a bit more difficult to show the effect of deduplication on Oracle Database because averages across diverse data makes pin-point focus impossible. However, as I was saying, I took some time on a freshly-installed XtremIO array and collected what I hope will be interesting information on the topic of deduplication.
Please take a look at Figure 1. To start the testing I created a 4TB XtremIO volume, attached it as a LUN to a test host and then created an XFS file system on it. Please be aware that the contents of an Oracle datafile is precisely the same whether stored in ASM or in a file system file. After the file system was created I used the SLOB database creation kit (SLOB/misc/create_database_kit) to create a small database with Oracle Database 12c. As Figure 1 shows, the small database consumed 11.83GB of logical space in the 4TB volume. However, since the data enjoyed a slight deduplication ratio of 1.1:1 and a healthy compression ratio of 3.3:1 for a 3.6:1 data reduction ratio, only 3.27GB physical space was consumed in the array.

Figure 1
The next step in the testing was to consume the majority of the 4TB file system with a BIGFILE tablespace. Figure 2 shows the DDL I used to create the tablespace.

Figure 2
Figure 3 shows the file system file that corresponds to the tablespace created with DDL in Figure 2.

Figure 3
After creating the 3.9TB BIGFILE tablespace I took a screenshot of the XtremIO GUI Dashboard. As Figure 4 shows, there was no deduplication! Instead, the data was compressed 4.0:1 resulting in only 977.66GB physical space being consumed in the array. So why in the world would I blog the opposite of what I said above? Why show the array did not, in fact, deduplicate the 3.9TB datafile? The answer is in the fact that I said there are duplicate data block in tablespaces. I didn’t say there are duplicate blocks in the same datafile!

Figure 4
To return the array to the state prior to the BIGFILE tablespace creation, I dropped the tablespace (including contents and datafiles thus unlinking the file) and then used the Linux fstrim(8) command to return the space to the array as shown in Figure 5.

Figure 5
Once the fstrim command completed I took another screenshot of the XtremIO GUI Dashboard as shown in Figure 6. Figure 6 shows that the array space utilization and data reduction had returned to that of what was seen before the BIGFILE tablespace creation.
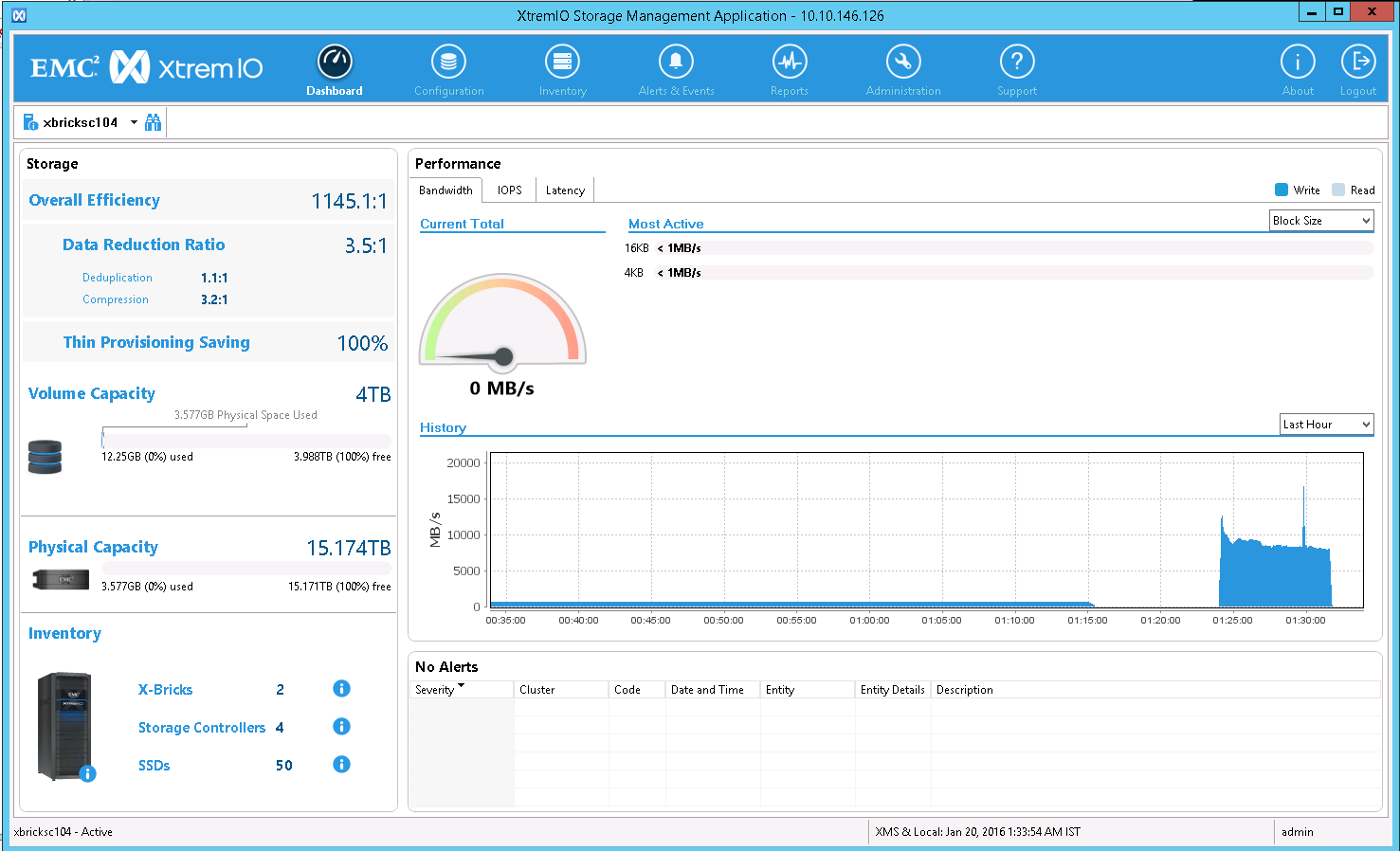
Figure 6
OK, Now For The Duplicate Data
The next step in the testing was to fill up the majority of the 4TB file system with SMALLFILE tablespaces. To do so I created 121 tablespaces each consisting of a single SMALLFILE datafile of 32GB. The output shown in Figure 7 is from a data dictionary query to display the size of each of the 121 datafiles and how the sum of these datafiles consumed 3.87TB of the 4TB file system.

Figure 7
That’s Duplicate Data
Once the file system was filled with SMALLFILE datafiles I took another screenshot of the XtremIO GUI Dashboard. Figure 8 shows that the SMALLFILE datafiles enjoyed a deduplication ratio 81.8:1 combined with a compression ratio of 3.8:1 resulting in a global data reduction rate of 306.9:1. Because of the significant data reduction rate only 12.68GB of physical space was consumed in the array in spite of the 3.79TB logical space (the sum of the SMALLFILE datafiles) being allocated.

Figure 8
So here we have it! I had a database created with Oracle Database 12c that consisted of 121 32GB files for roughly 3.8TB database size yet XtremIO deduplicated the data down by a factor of 82:1!
So arrays can deduplicate Oracle Database contents! Right? Well, yes, but it matters none whatsoever. Allow me to explain.
Oracle datafiles consist of initialized blocks but vast portions of that initialized content is the same from file to file. This fact can be seen with simple md5sum(1) output. Consider Figure 9 where you can see the output of the md5sum command used to compute Oracle datafile checksums but only after skipping the first 8,692 blocks (8KB blocks). It’s the first approximate 68MB of each datafile that is unique when a datafile is freshly initialized. Beyond that threshold we can see (Figure 9) that the rest of the file content is identical.
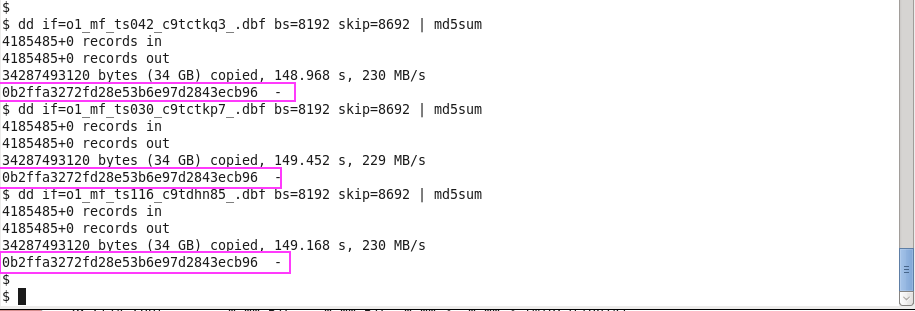
Figure 9
Thus far this blog post has proven that initialized, but empty, Oracle Database datafiles have duplicate data. As the title of this post says, however, it does not matter.
Introduce Application Data To The Mix
Figure 10 shows the commands I used to populate each of the 121 tablespaces with a single table. The table has the sparse characteristic we are all accustomed to with SLOB. That is, I am only creating a single row in each block. Moreover, I’m populating each of these 121 tables with the same application data! This is precisely why I say deduplication of Oracle Database doesn’t matter because it only holds true until any application data is loaded into the data blocks. Figure 10 shows this set of DDL commands.

Figure 10
After populating the blocks in each of the 121 tables (each residing in a dedicated SMALLFILE tablespace) with blocks containing just a single row of application data I took another screenshot of the XtremIO GUI Dashboard. Figure 11 shows how putting any data into the data blocks reverts the deduplication. Why? Well, remember that the block header of every block has the SCN of the last change made to the block. For this reason I can put the same application data in blocks and still have 100% unique blocks–at least at the 8KB level.
Please note that the application table I used to populate the 121 tables does not consume 100% of the data blocks in each of the SMALLFILE tablespaces. There were a few blocks remaining in each tablespace and thus there remained a scant amount of deduplication as seen in Figure 11. Most XtremIO customers see some insignificant deduplication in their Oracle Database environments. Some even see significant deduplication–at least until they insert data into the database.
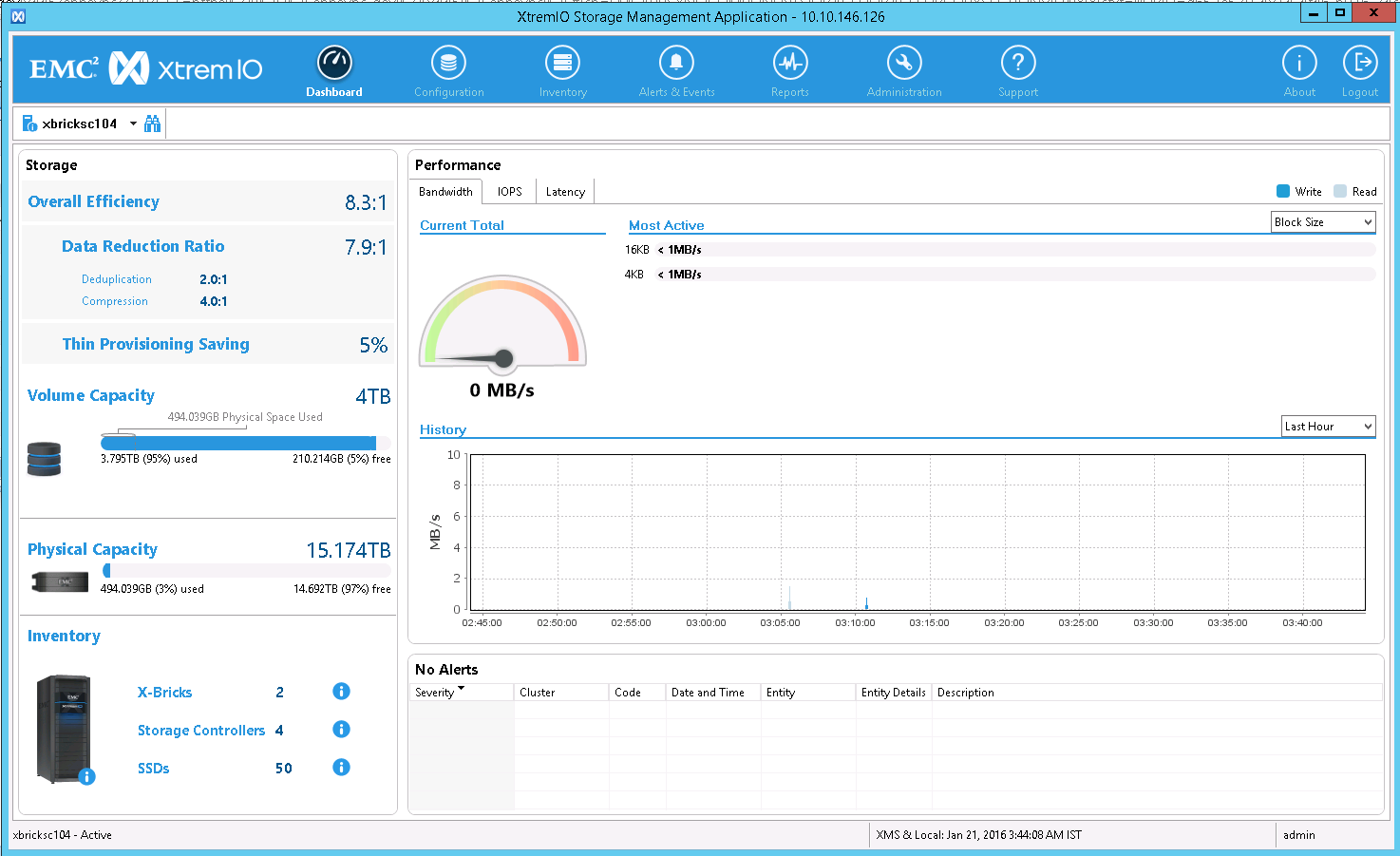
Figure 11
In a follow-up post I’ll say a few words about the deduplication granularity and how it affects the ability to achieve small amounts of deduplication of unused space in initialized data blocks. However, bear in mind that the net result of any deduplication of Oracle Database data files is that the only space that can be deduplicated is space that has never had application data in it. After all, a SQL DELETE command doesn’t remove data–it only marks it as free in the block.
Summary
I don’t think there are that many Oracle shops that have an urgent need for data reduction of space that’s never been used to store application data. I could be wrong. Until I find out either way, I say that yes you can see deduplication of Oracle Database datafiles but it doesn’t matter one bit.



Recent Comments