Folks that have read my blog for very long know that I routinely point out that Intel Xeon processors with fewer cores (albeit same TDP) get more throughput per core. Recently I had the opportunity to do some testing of a 2-socket host with 6-core Haswell EP Xeons (E5-2643v3) connected to networked all-flash storage. This post is about host capability so I won’t be elaborating on the storage. I’ll say that it was block storage, all-flash and networked.
Even though I test myriads of systems with modern Xeons it isn’t often I get to test the top-bin parts that aren’t core-packed. The Haswell EP line offers up to 18-core parts in a 145w CPU. This 6-core part is 135w and all cores clock up to 3.7GHz–not that clock speed is absolutely critical for Oracle Database performance mind you.
Taking It For a Spin
When testing for Oracle OLTP performance the first thing to do is measure the platform’s ability to deliver random single-block reads (db file sequential read). To do so I loaded 1TB scale SLOB 2.3 in the single-schema model. I did a series of tests to find a sweet-spot for IOPS which happened to be at 160 sessions. The following is a snippet of the AWR report from a 5-minute SLOB run with UPDATE_PCT=0. Since this host has a total of 12 cores I should think 8KB read IOPS of 625,000 per second will impress you. And, yes, these are all db file sequential reads.
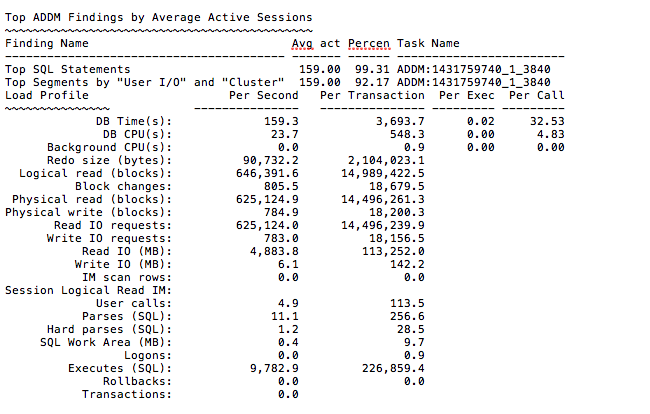
At 52,093 IOPS per CPU core I have to say this is the fastest CPU I’ve ever tested. It takes a phenomenal CPU to handle this rate of db file sequential read payload. So I began to wonder how this would compare to other generations of Xeons. I immediately thought of the Exadata Database Machine data sheets.
Before I share some comparisons I’d like to point out that there was a day when the Exadata data sheets made it clear that IOPS through the Oracle Database buffer cache costs CPU cycles–and, in fact, CPU is often the limiting factor. The following is a snippet from the Exadata Database Machine X2 data sheet that specifically points out that IOPS are generally limited by CPU. I/O buffered–and cached–in application shared memory is a CPU problem even if the buffers are never snooped. That is, in fact, why I invented SLOB way back in the early 1990s. I’ve never seen an I/O testing kit that can achieve more IOPS per DB CPU than is possible with SLOB.
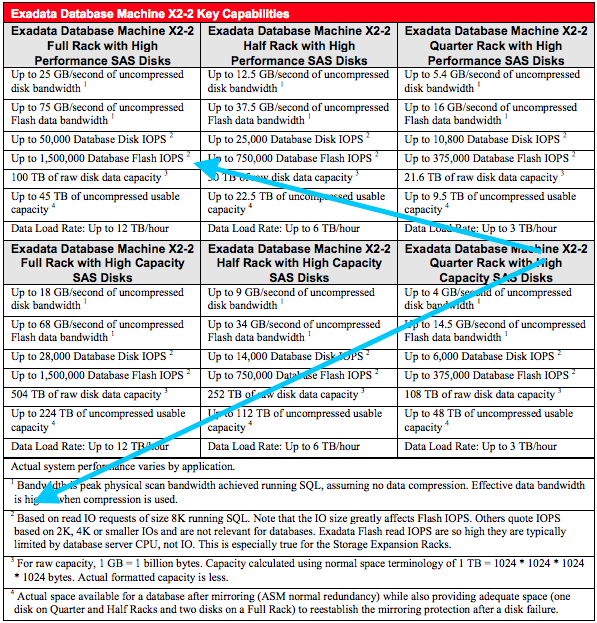
Oracle stopped using this foot note in the IOPS citations for Exadata Database Machine starting with the X3 generation. I have no idea why they stopped using this correct footnote. Perhaps they thought it was a bit like stating the obvious. I don’t know. Nonetheless, it is true that host CPU is a key limiting factor in a platform’s ability to cycle IOPS through the SGA. As an aside, please refer to this post about calibrate_io for more information about the processor ramifications of SGA versus PGA IOPS.
So, in spite of the fact that Oracle has stopped stating the limiting nature of host CPU on IOPS, I will simply assert the fact in this blog post. Quote me on this:
Everything is a CPU problem
And cycling IOPS through the Oracle SGA is a poster child for my quotable quote.
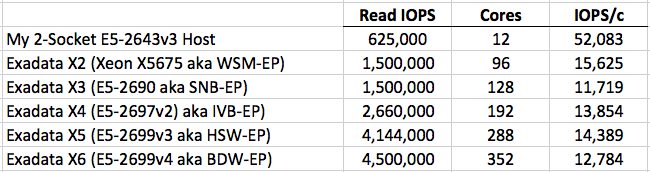
I think the best way to make my point is to simply take the data from the Exadata Database Machine data sheets and put it in a table that has a row for my E5-2643v3 results as well. Pictures speak thousands of words. And here you go:
AWR Report
If you’d like to read the full AWR report from the E5-2643v3 SLOB test that achieved 625,000 IOPS please click on the following link: AWR (click here).
References
X2 data sheet
X3 data sheet
X4 data sheet
X5 data sheet
X6 data sheet



{kind=link}
I always knew that lower number of cores was beneficial. .
if you go COD on any engineered system would you get any benefits from Turbo boost ? I.e if some cores are disabled would the other cores running at a higher clock speed redically alter the iops throughput ?
If you only saturate 6 cores in an 18 core part it will get more throughput per core. Yes.
Hi Kev
Just to understand the Exa table, is those for 8 node Exa Machines. So your single 2 socket produced 625,000 compared to the other numbers of 8 nodes… ?
Yes! I’m comparing a single host to 8 hosts in the Exadata (generations X2-X6) case
Curious… would you mind listing a bit more detail about the above test platform.
Could be interesting to build (public) a table showing CPU model (cores etc) and IOPS numbers, as you continue testing,…
Hello,
did you make any *nix kernel optimizations and what IO scheduler do you use?
did not touch the kernel and [deadline]
Hi Kevin, great post. Would be very interesting if we could to see the last table with the number of maximum LIOs/sec for each model (core). Thanks for your attention.
Exadata datasheets do not cite LIOPS so there is no data for that.
Kevin, I was thinking some benchmark did with Slob. I’d like to see how LIOs per core can to be compared with RPE2, for example.
Thanks
I’d say we petition @Daniel_Bowers to get SLOB cooked in to RPE2 🙂
If you have SLOB results, you don’t need RPE2! 🙂
Looking at RPE2/core yields something similar to Kevin’s table. The E5-2643v3 “advantage” over the others wouldn’t be quite as large, but it’s still large enough to make you question the sanity of those using the 2699 bin.