I occasionally get questions from customers and colleagues about performance expectations for the Oracle Database procedure called calibrate_io on XtremIO storage. This procedure must be executed in order to update the data dictionary. I assert, however, that it shouldn’t be used to measure platform suitability for Oracle Database physical I/O. The main reason I say this is because calibrate_io is a black box, as it were.
The procedure is, indeed, documented so it can’t possibly be a “black box”, right? Well, consider the fact that the following eight words are the technical detail provided in the Oracle documentation regarding what calibrate_io does:
This procedure calibrates the I/O capabilities of storage.
OK, I admit it. I’m being too harsh. There is also this section of the Oracle documentation that says a few more words about what this procedure does but not enough to make it useful as a platform suitability testing tool.
A Necessary Evil?
Yes, you must run calibrate_io. The measurements gleaned by calibrate_io are used by the query processing runtime (specifically involving Auto DOP functionality). The way I think of it is similar to how I think of gathering statistics for CBO. Gathering statistics generates I/O but I don’t care about the I/O it generates. I only care that CBO might have half a chance of generating a reasonable query plan given a complex SQL statement, schema and the nature of the data contained in the tables. So yes, calibrate_io generates I/O—and this, like I/O generated when gathering statistics, is I/O I do not care about. But why?
Here are some facts about the I/O generated by calibrate_io:
- The I/O is 100% read
- The reads are asynchronous
- The reads are buffered in the process heap (not shared buffers in the SGA)
- The code doesn’t even peek into the contents of the blocks being read!
- There is limited control over what tablespaces are accessed for the I/O
- The results are not predictable
- The results are not repeatable
My Criticisms
Having provided the above list of calibrate_io characteristics, I feel compelled to elaborate.
About Asynchronous I/O
My main issue with calibrate_io is it performs single-block random reads with asynchronous I/O calls buffered in the process heap. This type of I/O has nothing in common with the main reason random single-block I/O is performed by Oracle Database. The vast majority of single-block random I/O is known as db file sequential read—which is buffered in the SGA and is synchronous I/O. The wait event is called db file sequential read because each synchronous call to the operating system is made sequentially, one after the other by foreground processes. But there is more to SGA-buffered reads than just I/O.
About Server Metadata and Mutual Exclusion
Wrapped up in SGA-buffered I/O is all the necessary overhead of shared-cache management. Oracle can’t just plop a block of data from disk in the SGA and expect that other processes will be able to locate it later. When a process is reading a block into the SGA buffer cache it has to navigate spinlocks for the protected cache contents metadata known as cache buffers chains. Cache buffers chains tracks what blocks are in the buffer cache by their on-disk address. Buffer caches, like that in the SGA, also need to track the age of buffers. Oracle processes can’t just use any shared buffer. Oracle maintains buffer age in metadata known as cache buffers lru—which is also spinlock-protected metadata.
All of this talk about server metadata means that as the rate of SGA buffer cache block replacement increases—with newly-read blocks from storage—there is also increased pressure on these spinlocks. In other words, faster storage means more pressure on CPU. Scaling spinlocks is a huge CPU problem. It always has been—and even more so on NUMA systems. Testing I/O performance without also involving these critical CPU-intensive code paths provides false comfort when trying to determine platform suitability for Oracle Database.
Since applications do not drive random single-block asynchronous reads in Oracle Database, why measure it? I say don’t! Yes, execute calibrate_io, for reasons related to Auto DOP functionality, but not for a relevant reading of storage subsystem performance.
About User Data
This is one that surprises me quite frequently. It astounds me how quick some folks are to dismiss the importance of test tools that access user data. Say what? Yes, I routinely point out that neither calibrate_io nor Orion access the data that is being read from storage. All Orion and calibrate_io do is perform the I/O and let the data in the buffer remain untouched. It always seems strange to me when folks dismiss the relevance of this fact. Is it not database technology we are talking about here? Databases store your data. When you test platform suitability for Oracle Database I hold fast that it is best to 1) use Oracle Database (thus an actual SQL-driven toolkit as opposed to an external kit like Orion or fio or vdbench or any other such tool) and 2) that the test kit access rows of data in the blocks! I’m just that way.
Of course SLOB (and other SQL-driven test kits such as Swingbench do indeed access rows of data). Swingbench handily tests Oracle Database transaction capabilities and SLOB uses SQL to perform maximum I/O per host CPU cycle. Different test kits for different testing.
A Look At Some Testing Results
The first thing about calibrate_io I’ll discuss in this section is how the user is given no control or insight into what data segments are being accessed. Consider the following screenshot which shows:
- Use of the calibrate.sql script found under the misc directory in the SLOB kit (SLOB/misc/calibrate.sql) to achieve 371,010 peak IOPS and zero latency. This particular test was executed with a Linux host attached to an XtremIO array. Um, no, the actual latencies are not zero.
- I then created a 1TB tablespace. What is not seen in the screenshot is that all the tablespaces in this database are stored in an ASM disk group consisting of 4 XtremIO volumes. So the tablespace called FOO resides in the same ASM disk group. The ASM disk group uses external redundancy.
- After adding a 1TB tablespace to the database I once again executed calibrate_io and found that the IOPS increased 13% and latencies remained at zero. Um, no, the actual latencies are not zero!
- I then offlined the tablespace called FOO and executed calibrate_io to find that that IOPS fell back to within 1% of the first sample.
- Finally, I onlined the tablespace called FOO and the IOPS came back to within 1% of the original sample that included the FOO tablespace.
A Black Box
My objections to this result is calibrate_io is a black box. I’m left with no way to understand why adding a 1TB tablespace improved IOPS. After all, the tablespace was created in the same ASM disk group consisting of block devices provisioned from an all-flash array (XtremIO). There is simply no storage-related reason for the test result to improve as it did.

More IOPS, More Questions. I Prefer Answers.
I decided to spend some time taking a closer look at calibrate_io but since I wanted more performance capability I moved my testing to an XtremIO array with 4 X-Bricks and used a 2-Socket Xeon E5-2699v3 (HSW-EP 2s36c72t) server to drive the I/O.
The following screenshot shows the result of calibrate_io. This test configuration yielded 572,145 IOPS and, again, zero latency. Um, no, the real latency is not zero. The latencies are sub-millisecond though. The screen shot also shows the commands in the SLOB/misc/calibrate.sql file. The first two arguments to DBMS_RESOURCE_MANAGER.CALIBRATE_IO are “in” parameters. The value seen for parameter 2 is not the default. The next section of this blog post shows a variety of testing with varying values assigned to these parameters.
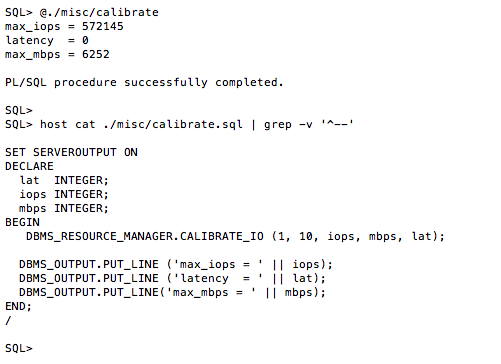
As per the documentation, the first parameter to calibrate_io is “approximate number of physical disks” being tested and the second parameter is “the maximum tolerable latency in milliseconds” for the single-block I/O.

As the table above shows I varied the “approximate number of physical disks” from 1 to 10,000 and the “maximum tolerable latency” from 10 to 20 and then 100. For each test I measured the elapsed time.
The results show us that the test requires twice the elapsed time with 1 approximate physical disk as it does for with 10,000 approximate physical disks. This is a nonsensical result but without any documentation on what calibrate_io actually does we are simply left scratching our heads. Another oddity is that with 10,000 approximate disks the throughput in megabytes per second is reduced by nearly 40% and that is without regard for the “tolerable latency” value. This is clearly a self-imposed limited within calibrate_io but why is the big question.
I’ll leave you, the reader, to draw your own conclusions about the data in the table. However, I use the set of results with “tolerable latency” set to 20 as validation for one of my indictments above. I stated calibrate_io is not predictable. Simply look at the set of results in the 20 “latency” parameter case and you too will conclude calibrate_io is not predictable.
So How Does CALIBRATE_IO Compare To SLOB?
I get this question quite frequently. Jokingly I say it compares in much the same way a chicken compares to a snake. They both lay eggs. Well, I should say they both perform I/O.
I wrote a few words above about how calibrate_io uses asynchronous I/O calls to test single-block random reads. I also have pointed out that SLOB performs the more correct synchronous single block reads. There is, however, an advanced testing technique many SLOB users employ to test PGA reads with SLOB as opposed to the typical SLOB reads into the SGA. What’s the difference? Well, revisit the section above where I discuss the server metadata management overhead related to reading blocks into the SGA. If you tweak SLOB to perform full scans you will test the flow of data through the PGA and thus the effect of eliminating all the shared-cache overhead. The difference is dramatic because, after all, “everything is a CPU problem.”
In a subsequent blog post I’ll give more details on how to configure SLOB for direct path with single-block reads!
To close out this blog entry I will show a table of test results comparing some key time model data. I collected AWR reports when calibrate_io was running as well as SLOB with direct path reads and then again with the default SLOB with SGA reads. Notice how the direct path SLOB increased IOPS by 19% just because blocks flowed through the PGA as opposed to the SGA. Remember, both of the SLOB results are 100% single-block reads. The only difference is the cache management overhead is removed. This is clearly seen by the difference in DB CPU. When performing the lightweight PGA reads the host was able to drive 29,884 IOPS per DB CPU but the proper SLOB results (SGA buffered) shows the host could only drive 19,306 IOPS per DB CPU. Remember DB CPU represents processor threads utilization on a threaded-processor. These results are from a 2s36c72t (HSW-EP) so these figures could also be stated as per DB CPU or per CPU thread.
If you are testing platforms suitability for Oracle it’s best to not use a test kit that is artificially lightweight. Your OLTP/ERP application uses the SGA, so test that!
The table also shows that calibrate_io achieved the highest IOPS but I don’t care one bit about that–because it isn’t true database I/O.

AWR Reports
I’d like to offer the following links to the full AWR reports summarized in the above table:
- The calibrate_io AWR.
- The SLOB AWR.
- The Direct Path Read SLOB AWR.
Additional Reading
- I recommend everything that Luca Canali writes and this deck about calibrate_io is no exception. Also see this Luca Canali post: http://externaltable.blogspot.de/2014/04/a-closer-look-at-calibrateio.html
- This post is more about calibrate_io as an I/O testing tool but I did mention Auto DOP. For more on Auto DOP please see the following posts:
- Mauro Pagano on Auto DOP in Oracle Database 12c
- Tim Hall on Adaptive Query Optimization
Summary
Use calibrate_io. Just don’t use it to test platform suitability for Oracle Database.



Always a pleasure reading your blogs, great seeing you write again.
Would be very keen to see a blog between the differences, values pro and cons of SLOB and Swingbench, what each is best for, what is it not.
Also, ye ye I always have allot of questions… Any chance you’ve gotten to the point where you can say what good and whats bad IO numbers, ye it’s a wide open question, lets “ring fence” it a bit.
Most of the Flash cards used by different vendors, their performance/capability I’d say is within 5% of each other.
So lets say, performance numbers for a single tray/brick, assuming most are using 8 cards, as to not over load the bus it’s connected to?
So whats a good IOps number to see per a common current intel CPU core.
hehehe nothing big 😉
(Mr Coke Light 😉 / Berlin )
Nice. Fair. Documented. Useful references.
I think of it like this: If I don’t know whether the i/o subsystem is configured even close to correctly, then the simplest thing you can find to just pump i/o will do.
After you’re pretty sure the i/o subsystem is not horrible all by itself and if you plan to run Oracle on it, then running SLOB to test capacity for Oracle is the best thing you can do. (And if it underperforms that might lead you to correcting something about the configuration or relative capacities of things you plan to license!)
Of course if you are starting with a delivered i/o subsystem from a competent vendor leaping directly to SLOB is unlikely to be a waste of time measuring something horribly broken at the i/o substrate.
Likewise a “black-box” from the vendor where you cannot really influence storage details.
(This was often NOT true prior, as you like it, to 1999, since neither vendors nor storage system administrators nor your average system administrator had a clue how to make spinning rust NOT self-interfere in the Oracle stack way below the threshold where everything is a cpu/memory problem).
mwf
Hi Mark,
I look at it this way:
1. You have to have a database to run SLOB
2. You have to have a database to run calibrate_io
3. You have to run calibrate_io to update the dictionary for sake of stuff like Auto DOP
4. You *should* run SLOB so you know what your *platform* can do
All I’m saying is ignore the output of calibrate_io. You and I are saying about the same thing.
nods. Sometimes something simpler upstream of installing a database is called for if there is serious doubt. That doesn’t happen much any more. SLOB, +42.
But Mark, it takes a database for calibrate_io. So maybe you are thinking about a touch test with something like Orion first? The way I see it is if you have Orion you have $ORACLE_HOME. You can point Orion to LUNS but if you have LUNS you *could* just make your ASM disk group. If you have an ASM disk group it takes a mere matter of minutes to use SLOB/misc/create_data_kit/cr_db.sql to lay down a SLOB database and a matter of minutes to load something like 15G scale SLOB. So if the LUNs don’t behave with SLOB->ASM->Storage then there is all the help tracing SQL, AWR, snapper, etc to work things out.
Either way I get your point. My point is since the goal is to get platform performance for Oracle…well…run Oracle.
well, calibrate IO is bad story. However, orion seems to be even worse. Surprisingly, on IBM Flash 840, Exadata Flash Cache in 11.2.0.3 / 11.2.0.4 it is not working. it seems it has troubles with latency under 1ms. SLOB is much better tool for testing oracle DB on Flash.
Great article Kevin, as usual of course 🙂
Just a small note CALIBRATE_IO is not mandatory anymore starting 12.1, AutoDOP will work anyway using a default value of 200MBPS.
I wouldn’t be surprised to see it go away completely considering the more granular info from V$OPTIMIZER_PROCESSING_RATE in 12c.