Regular readers of my blog know that I am a proponent of Oracle over NFS—albeit in the commodity computing space. I’ll leave those Superdomes and IBM System p servers with their direct SAN plumbing. So I must therefore be a huge fan of EMC’s Celerra MPFSi—the Multi-Path Filesystem, right? No, I’m not. This blog post is about why not MPFSi.
In this paper about EMC MPFSi, pictures speak a thousand words. But first, some of my own—with an Oracle-centric take. MPFSi would be just fine I suppose except it is both an NFS server-side architecture and a proprietary NFS client package. The following screen shot shows a basic diagram of Celerra with MPFSi. First, there are three components at the back end. One is the Celerra and another is an MDS 9509 Connectrix. The Celerra is there to service NAS filesystem metadata operations and the Connectrix with some iSCSI glue is there to transfer data requests in block form. That is, if you create a file and immediately write a block to it, you will have the file creation satisfied by the Celerra and the block write by the Connectrix. The final component is the SAN—since Celerra is a SAN-gateway. There is nothing wrong with SAN gateways by any means. I think SAN gateways are the best way to leverage a SAN for provisioning storage to the legacy monolithic Unix systems as well as the large number of commodity servers sitting on the same datacenter floor. That is, SAN to the legacy Unix system and SAN-gateway-NFS to the commodity servers. That’s tiered storage. Ultimately you have a single SAN holding all the data, but the provisioning and connectivity model of the gateway side is much better suited to large numbers of commodity servers than FCP. Here is the simplified topology of MPFSi:
NOTE, some browsers require you to right click->view.
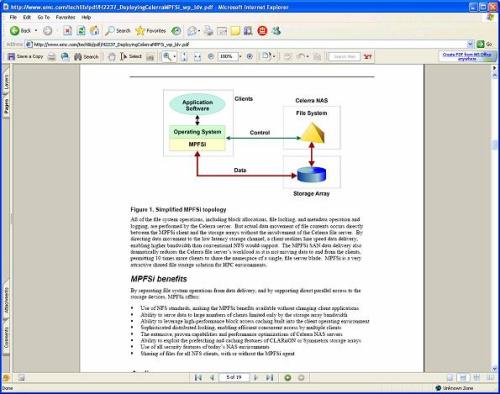
MPFSi requires NFS client-side software. The software presents a filesystem that is compatible with NFS protocols. There is an agent that intercepts NFS protocol messages and forwards them to the Celerra which then does with it what it will as per the MPFSi architecture as the following screen shot shows.
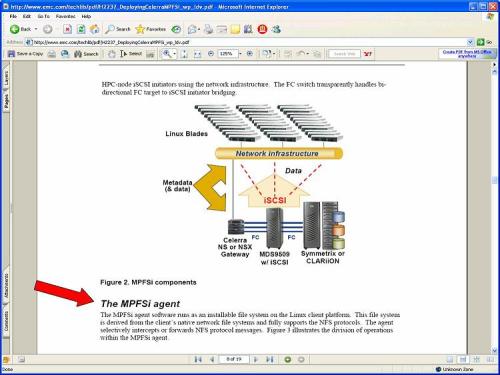
What’s This Have to do With Oracle?
So what’s the big deal? Well, I suppose if you absolutely need to stay with EMC as your SAN gateway vendor, then this is the choice for you. There are SAN-agnostic choices for SAN gateways as I’ve pointed out on this blog too many times. What about Oracle? Since Oracle10g supports NFS in the traditional model, I’m sure MPFSi works just fine. What about 11g? We’ve all heard “rumors” that 11g has a significant NFS-improvement focus. It is good enough with 10g, but 11g aims to make it an even better I/O model. That is good for Oracle’s On Demand hosting business since they use NFS exclusively. Will the 11g NFS enhancements function with MPFSi? Only an 11g beta program participant could tell you at the moment. I also know that the beta program legalese essentially states that participants can neither confirm nor deny whether they are, or are not, Oracle11g beta program participants. I’ll leave it at that.
Oracle over NFS is Not a Metadata Problem
When Oracle accesses files over NFS, there is no metadata overhead to speak of. Oracle is a simple lseek, read/write engine as far as NFS is concerned and there is no NFS client cache to get in the way either. Oracle opens files on NFS filesystems with the O_DIRECT flag. This alleviates a good deal of the overhead typical NFS exhibits. Oracle has an SGA, it doesn’t need NFS client-side cache. So MPFSi is not going to help where scalable NFS for Oracle is concerned. MPFSi better addresses the traditional problems with scaling home shares and so on.
Using Absolutely Dreadful Whitepapers as Collateral
Watch out if you read this ESG paper on EMC MPFSi because a belt sander might just drop from the ceiling and grind you to a fine powder as punishment for exposing yourself to such spam. This paper is a real jewel. If you dare risk the belt sander, I’ll leave it to you to read the whole thing. I’d like to point out, however, that it shamelessly uses relative performance numbers without the trouble of filling in any baselines for us in the performance section. For instance, the following shot shows a “graph” in the paper where the author makes the claim that MPFSi performs 300% better than normal NFS. This is typical chicanery—without the actual throughput achieved at the baseline, we can’t really ascertain what was tested. I have a $5 bet that the baseline was not, say, triple-bonded GbE delivering some 270+ MB/sec.




Recent Comments