This is not a post about why someone would want to deploy Oracle with a mix of files with varying support for asynchronous I/O. It is just a peek at how Oracle10g handles it. This blog post is a continuation of yesterday’s topic about analyzing DBWR I/O activity with strace(1).
I’ve said many times before that one of the things Oracle does not get sufficient credit for is the fact that the database adapts so well so such a tremendous variety of platforms. Moreover, each platform can be complex. Historically, with Linux for instance, some file systems support asynchronous I/O and others do not. With JFS on AIX, there are mount options to consider as is the case with Veritas on all platforms. These technologies offer deployment options. That is a good thing.
What happens when the initialization parameter filesystemio_options=asynch yet there are a mix of files that do and do not support asynchronous I/O? Does Oracle just crash? Does it offline files? Does it pollute the alert log with messages every time it tries an asynchronous I/O to a file that doesn’t support it? The answer is that it does not of that. It simply deals with it. It doesn’t throw the baby out with the bath water either. Much older versions of Oracle would probably have just marked the whole instance to the least common demoninator (synchronous).
Not Just A Linux Topic
I think the information in this blog post should be considered useful on all platforms. Sure, you can’t use strace(1) on a system that only offers truss(1), but you can do the same general analysis with either. The system calls will be different too. Whereas Oracle has to use the Linux-only libaio routines called io_submit(2)/io_getevents(2), all other ports[1] use POSIX asynchronous I/O (e.g., lio_listio,aio_write,etc) or other proprietary asynchronous I/O library routines.
Oracle Takes Charge
As I was saying, if you have some mix of technology where some files in the database do not support asynchronous I/O, yet you’ve configured the instance to use it, Oracle simply deals with the issue. There are no warnings. It is important to understand this topic in case you run into it though.
Mixing Synchronous with Asynchronous I/O
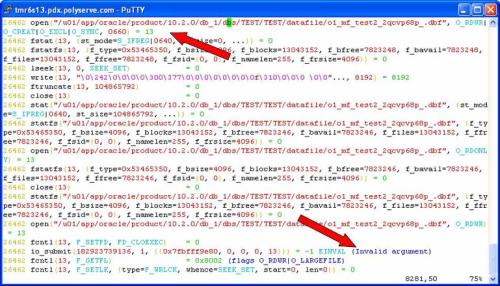
In the following screen shot I was viewing strace(1) output of a shadow process doing a tablespace creation. The instance was configured to use asynchronous I/O, yet the CREATE TABLESPACE command I issued was to create a file in a filesystem that does not support asynchronous I/O[2].Performing this testing on a platform where I can mix libaio asynchronous I/O and libc synchronous I/O with the same instance makes it easy to depict what Oracle is doing. At the first arrow in the screen shot, the OMF datafile is created with open(2) using the O_CREAT flag. The file descriptor returned is 13. The second arrow points to the first asynchronous I/O issued against the datafile. The io_submit(2) call failed with EINVAL indicating to Oracle that the operation is invalid for this file descriptor.
NOTE: Firefox users report that you need to right click->view the image to see these screen shots
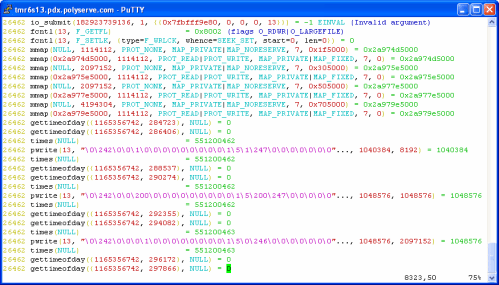
Now, Oracle could have raised an error and failed the CREATE TABLESPACE statement. It did not. Instead, the shadow process simply proceeded to create the datafile with synchronous I/O. The following screen shot shows the same io_submit(2) call failing at the first arrow, but nothing more than the invocation of some shared libraries (the mmap() calls) occurred between that failure and the first synchronous write using pwrite(2)—on the same file descriptor. The file didn’t need to be reopened or any such thing. Oracle simply fires off a synchronous write.
What Does This Have To Do With DBWR?
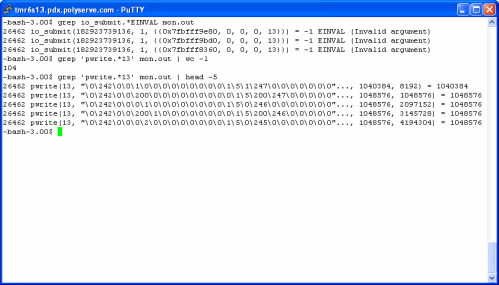
Once the tablespace was created, I set out to create tables in it with CTAS statements. To see what DBWR behaved like with this mix of asynchronous I/O support, I once again monitored DBWR with strace(1) sending the trace info to a file called mon.out. The following screen shot shows that the first attempts to flush SGA buffers to the file also failed with EINVAL. All was not lost however, the screen shot also shows that DBWR continued just fine using synchronous writes to this particular file. Note, DBWR does not have to perform this “discovery” on every flushing operation. Once the file is deemed unsuitable for asynchronous I/O, all subsequent I/O will be synchronous. Oracle just continues to work, without alarming the DBA.
How Would a Single DBWR Process Handle This?
So the next question is what does it mean to have a single database writer charged with the task of flushing buffers from the SGA to a mix of files where not all files support asynchronous I/O? It is not good. Now, as I said, Oracle could have just reverted the entire instance to 100% synchronous I/O, but that would not be in the best interest of performance. On the other hand, if Oracle is doing what I’m about to show you, it would be nice if it made one small alert log entry—but it doesn’t. That is why I’m blogging this (actually it is also because I’m a fan of Oracle at the platform level).
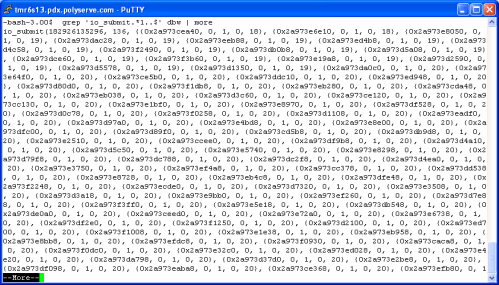
In the following screen shot, I use egrep(1) to pull occurrences from the DBWR strace(1) output file where io_submit(2) and pwrite(2) are intermixed. Again, this is a single DBWR flushing buffers from the SGA to files of varying asynchronous I/O support:
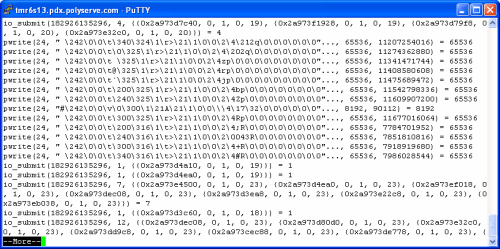
In this particular case, the very first io_submit(2) call flushed 4 buffers, 2 each to file descriptors 19 and 20. Before calling io_getevents(2) to process the completion of those asynchronous I/Os, DBWR proceeds to issue a series of synchronous writes to file descriptor 24 (another of the non-asynchronous I/O files in this database). By the way, notice that most of those writes to file descriptor 24 were multi-block DBWR writes. The problem with having one DBWR process intermixing synchronous with asynchronous I/O is that any buffers in the write batch bound for a synchronous I/O file will cause a delay in the instantiation of any buffer flushing to asynchronous I/O files. When DBWR walks an LRU to build a batch, it is not considering the lower-level OS support of asynchronous I/O on the file that a particular buffer will be written to. It just builds a batch based on buffer state and age. In short, synchronous I/O requests will cause a delay in the instantiation of subsequent asynchronous requests.
OK, so this is a two edged sword. Oracle handles this complexity nicely—much credit due. However, it is not entirely inconceivable that some of you out there have databases configured with a mix of asynchronous I/O support for your files. From platform to platform this can vary so much. Please be aware that this is not just a file system topic. It can also be a device driver issue. It is entirely possible to have a file system that generically supports asynchronous I/O created on a device where the device driver does not. This scenario will also result in EINVAL on asynchronous I/O calls. Here too, Oracle is likely doing the right thing—dealing with it.
What To Do?
Just use raw partitions. No, of course not. We should be glad that Oracle deals with such complexity so well. If you configure multiple database writers (not slaves) on a system that has a mix of asynchronous I/O support, you’ll likely never know the difference. But the topic is at least on your mind.





Recent Comments