Since my new job doesn’t really leave me with any time for blogging, I can at least refer to a really good blog post I recently found. If you are interested in setting up RAC using VMware, do not miss out on Frikkie Visser’s excellent “how-to” blog post about RAC on OEL with VMware. It is a very good post!
Archive Page 25
Setting up Oracle Database 11g Real Application Clusters with VMware. A Really Good Reference.
Published October 3, 2007 Oracle 11g Real Application Clusters , RAC VMware Leave a CommentAutomatic Databases Automatically Detect Storage Capabilities, Don’t They?
Published September 26, 2007 NFS CFS ASM , NFS Performance , oracle , Oracle 11g , Oracle Async I/O NFS , Oracle Asynchronous I/O , Oracle IO Calibration , Self Tuning Databases Leave a CommentDoug Burns has started an interesting blog thread about the Oracle Database 11g PARALLEL_IO_CAP_ENABLED parameter in his blog entry about Parallel Query and Oracle Database 11g. Doug is discussing Oracle’s new concept of built-in I/O subsystem calibration-a concept aimed at more auto-tuning database instances. The idea is that Oracle is trying to make PQ more aware of the down-wind I/O subsystem capability so that it doesn’t obliterate it with a flood of I/O. Yes, a kinder, gentler PQO.
I have to admit that I haven’t yet calibrated this calibration infrastructure. That is, I aim to measure the difference between what I know a given I/O subsystem is capable of and what DBMS_RESOURCE_MANAGER.CALIBRATE_IO thinks it is capable of. I’ll blog the findings of course.
In the meantime, I recommend you follow what Doug is up to.
A Really Boring Blog Entry
Nope, this is not just some look at that other cool blog over there post. At first glance I would hope that all the regular readers of my blog would wonder what value there is in throttling I/O all the way up in the database itself given the fact that there are several points at which I/O can/does get throttled downwind. For example, if the I/O is asynchronous, all operating systems have a maximum number of asynchronous I/O headers (the kernel structures used to track asynchronous I/Os) and other limiting factors on the number of outstanding asynchronous I/O requests. Likewise, SCSI kernel code is fit with queues of fixed depth and so forth. So why then is Oracle doing this up in the database? The answer is that Oracle can run on a wide variety of I/O subsystem architectures and not all of these are accessed via traditional I/O system calls. Consider Direct NFS for instance.
With Direct NFS you get disk I/O implemented via the remote procedure call interface (RPC). Basically, Oracle shoots the NFS commands directly at the NAS device as opposed to using the C library read/write routines on files in an NFS mount-which eventually filters down to the same thing anyway, but with more overhead. Indeed, there is throttling in the kernel for the servicing of RPC calls, as is the case with traditional disk I/O system calls, but I think you see the problem. Oracle is doing the heavy lifting that enables you to take advantage of a wide array of storage options-and not all of them are accessed with age-old traditional I/O libraries. And it’s not just DNFS. There is more coming down the pike, but I can’t talk about that stuff for several months given the gag order. If I could, it would be much easier for you to visualize the importance of DBMS_RESOURCE_MANAGER.CALIBRATE_IO. In the meantime, use your imagination. Think out of the box…way out of the box…
I’ve never seen that one before. I don’t do the Google AdSense thing so it looks like those two retailers got a freebie. What do I get?
NOTE: You may have to right click-> view to get a good look.

Not much to blog about. No, actually, I have an Olympic-sized swimming pool full of things to blog about, but I can’t. No time.
Since I’m working on a future Oracle product I’ve got RASUI on my mind. I thought this video seemed appropriate.
Polls Are Useless Without Critical Mass
Have all you readers participated in my (yet another) RAC poll? By the numbers I’d say not. Please take a moment and visit the poll. Thanks.
Two Terabytes of Flash Solid State Disk Anyone?
Published September 17, 2007 Flash Price Fixing , Flash SSD , NAND Flash , Solid State Disk Oracle 6 CommentsSeveral weeks ago my friends at Texas Memory Systems told me they’d soon have a Solid State Disk based upon NAND Flash technology. Right before I hopped on my flight back from Oracle HQ last Friday I got email from them with some technical info about the device. It looks like it is all public knowledge at this point since this PCWorld article hit the wire about 1 hour ago.
The product is called the RamSan-500. Hang on a second, I need to parse that. Let’s see, two syllables: “Ram” and “San.” SAN? A device that supports roughly .2ms reads (that’s the service times with a cache miss!) on a SAN with FCP? Sort of seems like funneling bullets through a garden hose.
What’s in a name, right? Well, this turns out to be a bit of a misnomer, because just like its cousin-the RamSan 400-the device will soon support 4x Infiniband (in spite of the fact that the current material suggests it is “in there” today). Time to market aside, that will make it a SCSI RDMA Protocol (SRP) target. Do you recall my recent post about Oracle’s August 2007 300GB TPC-H result that used Infiniband storage via SRP?
Now don’t get me wrong. Accessing this thing via FCP will still allow you to benefit from the tremendous throughput the device offers. And, indeed, regardless of the FCP overhead, returning all I/Os with sub-millisecond response time is going to pay huge dividends for sure. It’s just that more and more I’m leaning towards Infiniband-especially for transfers from a device with read service times that range from 15us (cache hit) to .2ms (cache miss). What about writes? It can handle 10,000 IOPS with 2ms service times. How would you like to stuff your sort TEMP segments in that? Oh what the heck, how about I just quote all their speed and feed data:
- Cache reads/writes:
- 15 microsecond access time
- Cache miss reads (reads from Flash):
- 100,000 random IOPS
- 2GB/second sustained bandwidth
- 200 microsecond latency
- Cache miss writes (writes to Flash)
- 10,000 random IOPS
- 2GB/second sustained bandwidth
- 2 millisecond latency.
Under the Covers
The RamSan-500 is more or less the same style of controller head the RamSan-400 has, so what’s so special? Well, putting NAND Flash as the backing store increases the capacity up to 2TB. T w o T e r a b y t e s!
So the question of the day is, “Where are you going to put your indexes, TEMP segements, hottest tables and Redo?” Anyone else think dangling round, brown spinning thingies off of orange glass cables doesn’t quite stack up?
Here’s a link to the RamSan-500 Web Page
QoS
I’ll blog at some point about QoS. After all, with a bunch of NAND Flash that looks and smells like a disk, storage management software that is smart enough to automagically migrate “hot” disk objects from slower to faster devices really starts to make sense.
Men in Black (DOJ)
I don’t pretend to know where TMS gets their Flash components, but it looks like “The Law” might end up being on their side if they get components from any of the alleged Flash providers suspected of a price-fixing scheme.
SQL Server on Linux and Windows Offers the Same Performance
Published September 14, 2007 AMD Memory Throughput 2 CommentsThis one really surprised me, mostly because I really don’t get a lot of exposure to Oracle Database on the Windows platform. Back in June I blogged about Oracle’s 10g Linux 100,000+ TPC-C result. That was a cool result for the types of reasons I blogged about then. However, it looks like that configuration has been pretty busy since the June announcement because today Oracle and HP announced an 11g TPC-C result on Windows of 102,454 TpmC on the same hardware-and achieved THE SAME THROUGHPUT! Well, give or take 1.5%. Here are links to the results:
That’s what I call platform parity, and I think it’s really cool. I wonder how SQL Server would perform in a Linux/Windows side-by-side benchmark? I know, I know, that was dopey.
By the way, I encourage you to take a peek at the full disclosure reports for these benchmarks. The Oracle configuration parameters were pretty straight forward. No voodoo.
Oops, I almost forgot to mention that the title of this blog entry was meant to be humorous.
Well, I’ve been in Oracle Server Technologies for a whopping week and in that short time I’m reassured of two constants:
- Blogging takes time (that I don’t have)
- Focusing on a single product, and more specifically a feature within a single product suite, makes a guy very pin-point minded
But, alas, I still need to stay well-rounded. So, thanks to a friend (and VP at a company I once worked for) for alerting me to the fact that Michael Stonebraker and others are blogging at The Database Column.
Yes, I’ll be reading that one. I don’t know if I’d recommend it to my readers though. That may sound odd, but most of my readers are practitioners of real, existing technology filling a production purpose. I expect the stuff on that blog to be laced with theory. Now, having said that, I have to remind myself that I believe well over 90% of my blog content is not exactly what one would call “ready to use” information.
All that aside, I just thought I’d poke my head up from the hole I’m in and make a quick blog entry. OK, there, I did…now it is back into the dungeon…but wait.
First Installment
Just because I said I was going to read it doesn’t imply I’m going to take it as some gulp from the fountain of omniscience.
For instance, in Michael Stonebraker’s post about row versus column orientation, he states:
[…] Vertica can be set-up and data loaded, typically in one day. The major vendors require weeks. Hence, the “out of box” experience is much friendlier. Also, Vertica beats all row stores on the planet – typically by a factor of 50. This statement is true for software only row stores as well as row stores with specialized hardware (e.g. Netezza, Teradata, Datallegro). The only engines that come closer are other column stores, which Vertica typically beats by around a factor of 10.
In my opinion that looks cut and pasted from a Vertica data sheet-but I don’t know. One thing I do know is that it seems unwise to say things like “all” and “typically by a factor of” in the same sentence. And this bit about “set-up and loaded” taking “weeks” for the “major vendors” is just plain goofy.
That’s my opinion. No, hold it, that’s my experience. I’ve loaded Oracle databases sized in the tens of terabytes that certainly didn’t take weeks!
Oracle ACE(s) Who Nominate Themselves…Oh, That Again?
Published September 10, 2007 oracle 14 CommentsDatabases are the Contents of Storage. Future Oracle DBAs Can Administer More. Why Would They Want To?
Published September 6, 2007 NFS CFS ASM , oracle , Oracle 11g , Oracle 11g Real Application Clusters , Oracle ASM , Oracle Automatic Memory Management , Oracle I/O Performance , Oracle performance , Oracle SMB , Oracle TPC-H , Oracle Unstructured Data , Oracle11g Leave a CommentI’ve taken the following quote from this Oracle whitepaper about low cost storage:
A Database Storage Grid does not depend on flawless execution from its component storage arrays. Instead, it is designed to tolerate the failure of individual storage arrays.
In spite of the fact that the Resilient Low-Cost Storage Initiative program was decommissioned along with the Oracle Storage Compatability Program, the concepts discussed in that paper should be treated as a barometer of the future of storage for Oracle databases-with two exceptions: 1) Fibre Channel is not the future and 2) there’s more to “the database” than just the database. What do I mean by point 2? Well, with features like SecureFiles, we aren’t just talking rows and columns any more and I doubt (but I don’t know) that SecureFiles is the end of that trend.
Future Oracle DBAs
Oracle DBAs of the future become even more critical to the enterprise since the current “stove-pipe” style IT organization will invariably change. In today’s IT shop, the application team talks to the DBA team who talks to the Sys Admin team who tlks to the Storage Admin team. All this to get an application to store data on disk through a Oracle database. I think that will be the model that remains for lightly-featured products like MySQL and SQL Server, but Oracle aims for more. Yes, I’m only whetting your appetite but I will flesh out this topic over time. Here’s food for thought: Oracle DBAs should stop thinking their role in the model stops at the contents of the storage.
So while Chen Shapira may be worried that DBAs will get obviated, I’d predict instead that Oracle technology will become more full-featured at the storage level. Unlike the stock market where past performance is no indicator of future performance, Oracle has consistently brought to market features that were once considered too “low-level” to be in the domain of a Database vendor.
The IT industry is going through consolidation. I think we’ll see Enterprise-level IT roles go through some consolidation over time as well. DBAs who can wear more than “one hat” will be more valuable to the enterprise. Instead of thinking about “encroachment” from the low-end database products, think about your increased value proposition with Oracle features that enable this consolidation of IT roles-that is, if I’m reading the tea leaves correctly.
How to Win Friends and Influence People
Believe me, my positions on Fibre Channel have prompted some fairly vile emails in my inbox-especially the posts in my Manly Man SAN series. Folks, I don’t “have it out”, as they say, for the role of Storage Administrators. I just believe that the Oracle DBAs of today are on the cusp of being in control of more of the stack. Like I said, it seems today’s DBA responsibilities stop at the contents of the storage-a role that fits the Fibre Channel paradigm quite well, but a role that makes little sense to me. I think Oracle DBAs are capable of more and will have more success when they have more control. Having said that, I encourage any of you DBAs who would love to be in more control of the storage to look at my my post about the recent SAN-free Oracle Data Warehouse. Read that post and give considerable thought to the model it discusses. And give even more consideration to the cost savings it yields.
The Voices in My Head
Now my alter ego (who is a DBA, whereas I’m not) is asking, “Why would I want more control at the storage level?” I’ll try to answer him in blog posts, but perhaps some of you DBAs can share experiences where performance or availability problems were further exacerbated by finger pointing between you and the Storage Administration group.
Note to Storage Administrators
Please, please, do not fill my email box with vitriolic messages about the harmony today’s typical stove-pipe IT organization creates. I’m not here to start battles.
Let me share a thought that might help this whole thread make more sense. Let’s recall the days when an Oracle DBA and a System Administrator together (yet alone) were able to provide Oracle Database connectivity and processing for thousands of users without ever talking to a “Storage Group.” Do you folks remember when that was? I do. It was the days of Direct Attach Storage (DAS). The problem with that model was that it only took until about the late 1990s to run out of connectivity-enter the Fibre Channel SAN. And since SANs are spokes attached to hubs of storage systems (SAN arrays), we wound up with a level of indirection between the Oracle server and its blocks on disk. Perhaps there are still some power DBAs that remember how life was with large numbers of DAS drives (hundreds). Perhaps they’ll recall the level of control they had back then. On the other hand, perhaps I’m going insane, but riddle me this (and feel free to quote me elsewhere):
Why is it that the industry needed SANs to get more than a few hundred disks attached to a high-end Oracle system in the late 1990s and yet today’s Oracle databases often reside on LUNs comprised of a handful of drives in a SAN?
The very thought of that twist of fate makes me feel like a fish flopping around on a hot sidewalk. Do you remember my post about capacity versus spindles? Oh, right, SAN cache makes that all better. Uh huh.
Am I saying the future is DAS? No. Can I tell you now exactly what model I’m alluding to? Not yet, but I enjoy putting out a little food for thought.
What Oracle Topic Is On Your Coffee Table?
Published September 6, 2007 Oracle I/O Performance , Oracle OTLP , Oracle performance Leave a CommentI’ve received a couple of emails over the last few weeks in which readers asked me what my favorite blog posts are on my own blog. I’d have to sift through old posts to answer that definitively, but one recent post comes to mind. I think my recent post about why Oracle shops generally aren’t realizing the full potential of their hard drives is one of my favorites.
Blog Changes
Now that I’ve left HP/PolyServe, I’ve gotten a few emails from readers looking for files that I linked to that resided on HP/PolyServe systems. I’ve also gotten quite a few emails about pages found by search engines, but don’t load (Error 404) once you come to my site. As for the latter, there are a good number of posts that I’ve taken offline. Sorry, but that is just how things go. As for the files content, I’ll try to make them available on the OakTable website. The first to get this treatment is the Silly Little Benchmark that I spoke of in some of my NUMA-related posts such as Oracle on Opteron with Linux–The NUMA Angle. Introducing the Silly Little Benchmark.
I’ll be fixing those refrences. In the meaintime, here is a link to the Silly Little Benchmark.
There is a difference between jumping ship and making an orderly transfer from one ship to another. I tend to think of jumping ship as something one does when it is sinking. I’m not jumping ship.
For the last 6 years at PolyServe, and 10 years before that at Sequent Computer Systems, I’ve had the honor to work with some of the brightest software folks around. See, the brain power behind PolyServe is a lot of the heavy-hitting Unix kernel engineers from Sequent Computer Systems. They left after IBM bought Sequent. I joined them shortly thereafter, leaving Veritas to do so. I think it is fitting to quote my long time friend and fellow OakTable Network member, James Morle. In Oracle Insights: Tales of the Oak Table, James says:
…around the same time Sequent appeared with a good story, great attitude, and some of the best software technicians I have worked with from a hardware company.
I know what he means. But I’m leaving. I did my part at PolyServe, HP acquired us. Getting taken up in a corporate takeover means a new adventure. When faced with a new adventure it sometimes makes sense to open up to other, sometimes better, opportunity. This is one of those cases.
Next week I start a new chapter. I’ll be taking a role in Oracle’s Server Technologies group. Fortunately for me, I’ve had pretty close ties with a lot of these folks dating back to the mid-1990s and my work in Sequent’s Advanced Oracle Engineering group.
So, I’m transferring to a different ship. A ship that I am very familiar with. A ship with crew that I respect and with whom it’ll be an honor to work.
What Is Good Throughput With Oracle Over NFS?
Published August 31, 2007 NFS CFS ASM , oracle , Oracle NAS , Oracle NFS , Oracle on NFS 8 CommentsThe comment thread on my blog entry about the simplicity of NAS for Oracle got me thinking. I can’t count how many times I’ve seen people ask the following question:
Is N MB/s good throughput for Oracle over NFS?
Feel free to plug in any value you’d like for N. I’ve seen people ask if 40MB/s is acceptable. I’ve seen 60, 80, name it-I’ve seen it.
And The Answer Is…
Let me answer this question here and now. The acceptable throughput for Oracle over NFS is full wire capacity. Full stop! With Gigabit Ethernet and large Oracle transfers, that is pretty close to 110MB/s. There are some squeak factors that might bump that number one way or the other but only just a bit. Even with the most hasty of setups, you should expect very close to 100MB/s straight out of the box-per network path. I cover examples of this in depth in this HP whitepaper about Oracle over NFS.
The steps to a clean bill of health are really very simple. First, make sure Oracle is performing large I/Os. Good examples of this are tablespace CCF (create contiguous file) and full table scans with port-maximum multi-block reads. Once you verify Oracle is performance large I/Os, do the math. If you are not close to 100MB/s on a GbE network path, something is wrong. Determining what’s wrong is another blog entry. I want to capitalize on this nagging question about expectations. I reiterate (quoting myself):
Oracle will get line speed over NFS, unless something is ill-configured.
Initial Readings
I prefer to test for wire-speed before Oracle is loaded. The problem is that you need to mimic Oracle’s I/O. In this case I mean Direct I/O. Let’s dig into this one a bit.
I need something like a dd(1) tool that does O_DIRECT opens. This should be simple enough. I’ll just go get a copy of the oss.oracle.com coreutils package that has O_DIRECT tools like dd(1) and tar(1). So here goes:
[root@tmr6s15 DD]# ls ../coreutils-4.5.3-41.i386.rpm
../coreutils-4.5.3-41.i386.rpm
[root@tmr6s15 DD]# rpm2cpio < ../coreutils-4.5.3-41.i386.rpm | cpio -idm
11517 blocks
[root@tmr6s15 DD]# ls
bin etc usr
[root@tmr6s15 DD]# cd bin
[root@tmr6s15 bin]# ls -l dd
-rwxr-xr-x 1 root root 34836 Mar 4 2005 dd
[root@tmr6s15 bin]# ldd dd
linux-gate.so.1 => (0xffffe000)
libc.so.6 => /lib/tls/libc.so.6 (0x00805000)
/lib/ld-linux.so.2 (0x007ec000)
I have an NFS mount exported from an HP EFS Clustered Gateway (formerly PolyServe):
$ ls -l /oradata2 total 8388608 -rw-r--r-- 1 root root 4294967296 Aug 31 10:15 file1 -rw-r--r-- 1 root root 4294967296 Aug 31 10:18 file2 $ mount | grep oradata2 voradata2:/oradata2 on /oradata2 type nfs (rw,bg,hard,nointr,tcp,nfsvers=3,timeo=600,rsize=32768,wsize=32768,actimeo=0,addr=192.168.60.142)
Let’s see what the oss.oracle.com dd(1) can do reading a 4GB file and over-writing another 4GB file:
$ time ./dd --o_direct=1048576,1048576 if=/oradata2/file1 of=/oradata2/file2 conv=notrunc 4096+0 records in 4096+0 records out real 1m32.274s user 0m3.681s sys 0m8.057s
Test File Over-writing
What’s this bit about over-writing? I recommend using conv=notrunc when testing write speed. If you don’t, the file will be truncated and you’ll be testing write speeds burdened with file growth. Since Oracle writes the contents of files (unless creating or extended a datafile), it makes no sense to test writes to a file that is growing. Besides, the goal is to test the throughput of O_DIRECT I/O via NFS, not the filer’s ability to grow a file. So what did we get? Well, we transferred 8GB (4GB in, 4GB out) and did so in 92 seconds. That’s 89MB/s and honestly, for a single path I would actually accept that since I have done absolutely no specialized tuning whatsoever. This is straight out of the box as they say. The problem is that I know 89MB/s is not my typical performance for one of my standard deployments. What’s wrong?
The dd(1) package supplied with the oss.oracle.com coreutils has a lot more in mind than O_DIRECT over NFS. In fact, it was developed to help OCFS1 deal with early cache-coherency problems. It turned out that mixing direct and non-direct I/O on OCFS was a really bad thing. No matter, that was then and this is now. Let’s take a look at what this dd(1) tool is doing:
$ strace -c ./dd --o_direct=1048576,1048576 if=/oradata2/file1 of=/oradata2/file2 conv=notrunc 4096+0 records in 4096+0 records out Process 32720 detached % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 56.76 4.321097 1054 4100 1 read 22.31 1.698448 415 4096 fstatfs 10.79 0.821484 100 8197 munmap 9.52 0.725123 177 4102 write 0.44 0.033658 4 8204 mmap 0.16 0.011939 3 4096 fcntl 0.02 0.001265 70 18 12 open 0.00 0.000178 22 8 close 0.00 0.000113 23 5 fstat 0.00 0.000091 91 1 execve 0.00 0.000015 2 8 rt_sigaction 0.00 0.000007 2 3 brk 0.00 0.000006 3 2 mprotect 0.00 0.000004 4 1 1 access 0.00 0.000002 2 1 uname 0.00 0.000002 2 1 arch_prctl ------ ----------- ----------- --------- --------- ---------------- 100.00 7.613432 32843 14 total
Eek! I’ve paid for a 1:1 fstatfs(2) and fcntl(2) per read(2) and a mmap(2)/munmap(2) call for every read(2)/write(2) pair! Well, that wouldn’t be a big deal on OCFS since fstatfs(2) is extremely cheap and the structure contents only changes when filesystem attributes change. The mmap(2)/munmap(2) costs a bit, sure, but on a local filesystem it would be very cheap. What I’m saying is that this additional call overhead wouldn’t laden down OCFS throughput with the –o_direct flag-but I’m not blogging about OCFS. With NFS, this additional call overhead is way to expensive. All is not lost.
I have my own coreutils dd(1) that I implements O_DIRECT open(2). You can do this too, it is just GNU after all. With this custom GNU coreutils dd(1) I have, the call profile is nothing more than read(2) and write(2) back to back. Oh, I forgot to mention, the oss.oracle.com dd(1) doesn’t work with /dev/null or /dev/zero since it tries to throw an O_DIRECT open(2) at those devices which makes the tool croak. My dd(1) checks if in or out is /dev/null or /dev/zero and omits the O_DIRECT for that side of the operation. Anyway, here is what this tool got:
$ time dd_direct if=/oradata2/file1 of=/oradata2/file2 bs=1024k conv=notrunc 4096+0 records in 4096+0 records out real 1m20.162s user 0m0.008s sys 0m1.458s
Right, that’s more like it-80 seconds or 102 MB/s. Shaving those additional calls off brought throughput up 15%.
What About Bonding/Teaming NICS
Bonding NICs is a totally different story as I point out somewhat in this paper about Oracle Database 11g Direct NFS. You can get very mixed results if the network interface over which you send NFS traffic is bonded. I’ve seen 100% scalability of NICs in a bonded pair and I’ve seen as low as 70%. If you are testing a bonded pair, set your expectations accordingly.
The Most Horribly Botched Oracle Database 10g Real Application Clusters Install Attempt.
Published August 29, 2007 Real Application Clusters Installation , Unbreakable Linux 6 CommentsNow don’t get me wrong. What I’m blogging about is not really an Oracle Database 10g Real Application Clusters (RAC) problem. All of the problems I will mention in this entry were clearly related to a botched configuration at the OS level. Since Oracle10g will be around for a long time, I suspect that some day someone else might run into this sort of a problem and I aim to make their lives easier. That said, there could be some goodies in here for all the regular readers of this blog.
The Scenario
I took the brand new 4-node RAC cluster I have in the lab and aimed to see how much the oracle-validated-100-4el4x86_64.rpm package assists in setting up the system in preparation for a RAC install. I was excited since this was the first 2-socket Xeon “Cloverdale” 5355-based cluster I’ve had the chance to test. These processors are murderously fast so I was chomping at the bits to give them a whirl.
The systems were loaded with RHEL4 U4 x86_64. I executed the oracle-validated-100-4el4x86_64.rpm package and here is what it returned:
# rpm -ivh oracle-validated-1.0.0-4.el4.x86_64.rpm
warning: oracle-validated-1.0.0-4.el4.x86_64.rpm: V3 DSA signature: NOKEY, key ID b38a8516
error: Failed dependencies:
/usr/lib/libc.so is needed by oracle-validated-1.0.0-4.el4.x86_64
control-center is needed by oracle-validated-1.0.0-4.el4.x86_64
fontconfig >= 2.2.3-7.0.1 is needed by oracle-validated-1.0.0-4.el4.x86_64
gnome-libs is needed by oracle-validated-1.0.0-4.el4.x86_64
libdb.so.3()(64bit) is needed by oracle-validated-1.0.0-4.el4.x86_64
libstdc++.so.5()(64bit) is needed by oracle-validated-1.0.0-4.el4.x86_64
xscreensaver is needed by oracle-validated-1.0.0-4.el4.x86_64
Suggested resolutions:
compat-db-4.1.25-9.x86_64.rpm
compat-libstdc++-33-3.2.3-47.3.x86_64.rpm
control-center-2.8.0-12.rhel4.5.x86_64.rpm
gnome-libs-1.4.1.2.90-44.1.x86_64.rpm
xscreensaver-4.18-5.rhel4.11.x86_64.rpm
So I chased down what was recommended and installed those RPMs as well:
# cat > /tmp/list
compat-db-4.1.25-9.x86_64.rpm
compat-libstdc++-33-3.2.3-47.3.x86_64.rpm
control-center-2.8.0-12.rhel4.5.x86_64.rpm
gnome-libs-1.4.1.2.90-44.1.x86_64.rpm
xscreensaver-4.18-5.rhel4.11.x86_64.rpm
# rpm -ivh --nodeps `cat /tmp/list | xargs echo`
warning: compat-db-4.1.25-9.x86_64.rpm: V3 DSA signature: NOKEY, key ID db42a60e
Preparing... ########################################### [100%]
1:xscreensaver ########################################### [ 20%]
2:compat-db ########################################### [ 40%]
3:compat-libstdc++-33 ########################################### [ 60%]
4:control-center ########################################### [ 80%]
5:gnome-libs ########################################### [100%]
At this point I think I should have been ready to install Oracle Clusterware (CRS). Well, the install failed miserably during the linking phase and-shame on me-I didn’t save any of the logs or screen shots. No matter, I can still make a good blog entry out of this-so long as you are willing to believe that the linking phase of the CRS install failed. I decided to clean up the botched installation and use my normal installation process.
The approach I generally take is to look at a comparable Oracle Validated Configuration and pull the list of RPMs specified. And that is precisely what I did:
$ cat > /tmp/list
binutils-2.15.92.0.2-21.x86_64.rpm
compat-db-4.1.25-9.x86_64.rpm
compat-libstdc++-33-3.2.3-47.3.x86_64.rpm
control-center-2.8.0-12.rhel4.5.x86_64.rpm
gcc-3.4.6-3.x86_64.rpm
gcc-c++-3.4.6-3.x86_64.rpm
glibc-2.3.4-2.25.i686.rpm
glibc-2.3.4-2.25.x86_64.rpm
glibc-devel-2.3.4-2.25.i386.rpm
glibc-devel-2.3.4-2.25.x86_64.rpm
glibc-common-2.3.4-2.25.x86_64.rpm
glibc-headers-2.3.4-2.25.x86_64.rpm
glibc-kernheaders-2.4-9.1.98.EL.x86_64.rpm
gnome-libs-1.4.1.2.90-44.1.x86_64.rpm
libgcc-3.4.6-3.x86_64.rpm
libstdc++-3.4.6-3.x86_64.rpm
libstdc++-devel-3.4.6-3.x86_64.rpm
libaio-0.3.105-2.x86_64.rpm
make-3.80-6.EL4.x86_64.rpm
pdksh-5.2.14-30.3.x86_64.rpm
sysstat-5.0.5-11.rhel4.x86_64.rpm
xorg-x11-deprecated-libs-6.8.2-1.EL.13.36.x86_64.rpm
xorg-x11-deprecated-libs-6.8.2-1.EL.13.36.i386.rpm
xscreensaver-4.18-5.rhel4.11.x86_64.rpm
# rpm -ivh --nodeps `cat /tmp/list | xargs echo`
[…output deleted…]
# rpm -ivh oracle-validated-1.0.0-4.el4.x86_64.rpm
warning: oracle-validated-1.0.0-4.el4.x86_64.rpm: V3 DSA signature: NOKEY, key ID b38a8516
error: Failed dependencies:
/usr/lib/libc.so is needed by oracle-validated-1.0.0-4.el4.x86_64
fontconfig >= 2.2.3-7.0.1 is needed by oracle-validated-1.0.0-4.el4.x86_64
# rpm -ivh fontconfig-2.2.3-7.x86_64.rpm
warning: fontconfig-2.2.3-7.x86_64.rpm: V3 DSA signature: NOKEY, key ID db42a60e
Preparing... ########################################### [100%]
package fontconfig-2.2.3-7 is already installed
So, once again I should have been ready to go. That was not the case. I got the following stream of error output when I ran vipca:
# sh ./vipca PRKH-1010 : Unable to communicate with CRS services. [PRKH-1000 : Unable to load the SRVM HAS shared library [PRKN-1008 : Unable to load the shared library "srvmhas10" or a dependent library, from LD_LIBRARY_PATH="/opt/oracle/crs/jdk/jre/lib/i386/client:/opt/oracle/crs/jdk/jre/lib/i386:/opt/oracle/crs/jdk/jre/.. /lib/i386:/opt/oracle/crs/lib32:/opt/oracle/crs/srvm/lib32:/opt/oracle/crs/lib:/opt/oracle/crs/srvm/lib:" [java.lang.UnsatisfiedLinkError: /opt/oracle/crs/lib32/libsrvmhas10.so: libclntsh.so.10.1: cannot open shared object file: No such file or directory]]] PRKH-1010 : Unable to communicate with CRS services. [PRKH-1000 : Unable to load the SRVM HAS shared library [PRKN-1008 : Unable to load the shared library "srvmhas10" or a dependent library, from LD_LIBRARY_PATH="/opt/oracle/crs/jdk/jre/lib/i386/client:/opt/oracle/crs/jdk/jre/lib/i386:/opt/oracle/crs/jdk/jre/.. /lib/i386:/opt/oracle/crs/lib32:/opt/oracle/crs/srvm/lib32:/opt/oracle/crs/lib:/opt/oracle/crs/srvm/lib:" [java.lang.UnsatisfiedLinkError: /opt/oracle/crs/lib32/libsrvmhas10.so: libclntsh.so.10.1: cannot open shared object file: No such file or directory]]] PRKH-1010 : Unable to communicate with CRS services. [PRKH-1000 : Unable to load the SRVM HAS shared library [PRKN-1008 : Unable to load the shared library "srvmhas10" or a dependent library, from LD_LIBRARY_PATH="/opt/oracle/crs/jdk/jre/lib/i386/client:/opt/oracle/crs/jdk/jre/lib/i386:/opt/oracle/crs/jdk/jre/.. /lib/i386:/opt/oracle/crs/lib32:/opt/oracle/crs/srvm/lib32:/opt/oracle/crs/lib:/opt/oracle/crs/srvm/lib:" [java.lang.UnsatisfiedLinkError: /opt/oracle/crs/lib32/libsrvmhas10.so: libclntsh.so.10.1:
Egad! What I’m about to tell you should prove beyond the shadow of a doubt that I am not a DBA! I don’t need VIPs or gsd or srvctl for that matter. My test harnesses do not use any of that-at least not the test harness I was intending to use for this specific battery of testing. So, I ignored the vipca problem and figured I’d just install the database and get to work. I’ve never before seen what I’m about to show you.
During the installation of the database, OUI detected all nodes of the cluster so I thought I might be able to sneak this one through. however, during the installation of the database, OUI presented a dialogue for database updates. Now, this is seriously odd since this was a freshly built cluster. There were no other databases installed, but that isn’t the most peculiar aspect of this dialogue. Check it out:
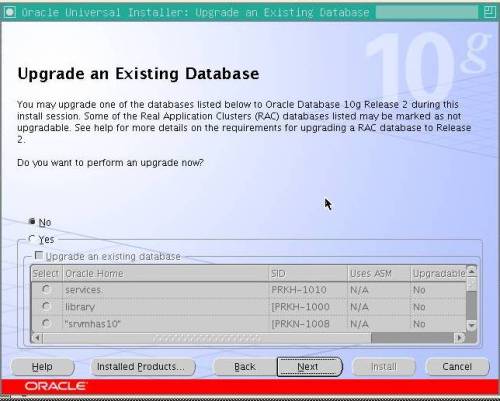
That is strangely beyond strange! I’m not sure if you can tell what that is but the cells in the dialogue are populated with error output (PRKH-* and LD_LIBRARY_PATH, etc). Wow, that was crazy. What I’m about to tell you should be proof positive that not only am I not a DBA, I do things that are only done by someone who has no idea what a DBA is! I needed the database installed and I didn’t have any databases to upgrade, so I thought I’d ignore this database upgrade mess and push on. Bad idea.
Of course the install was a total failure. I spent some time figuring out what was going on and then it dawned on me. I forgot to install the 32bit glibc-devel RPM. After doing so I cleaned up the mess, walked through the install again and viola-no problems.
The Moral of the Story
Don’t forget the required 32bit library when installing 10g on x86_64 Linux and pay particular attention to the fact that neither the Validated Configuration list of RPMS, nor the oracle-validated-100-4el4x86_64.rpm package had any mention of this library.
I hope it helps someone, someday. Nonetheless, that was a weird screen shot wasn’t it?
Oracle Database 11g Initialization Parameters. A Digest.
Published August 27, 2007 Oracle 11g , Oracle Database 11g , Oracle11g initialization parameters Leave a CommentHoward Rogers has a series of blog entries about Oracle11g initialization parameters. I recommend it. Here is a link:



Recent Comments