BLOG UPDATE 2015.07.24: For all testing recipes please visit the SLOB Recipes section of kevinclosson.net/slob
This is Part II in a series. Part I can be found here (click here). Part I in the series covered a very simple case of SLOB data loading. This installment is aimed at how one can use SLOB as a platform test for a unique blend of concurrent, high-bandwidth data loading, index creation and CBO statistics gathering.
Put SLOB On The Box – Not In a Box
As a reminder, the latest SLOB kit is always available here: kevinclosson.net/slob .
Often I hear folks speak of what SLOB is useful for and the list is really short. The list is so short that a single acronym seems to cover it—IOPS, just IOPS and nothing else. SLOB is useful for so much more than just testing a platform for IOPS capability. I aim to make a few blog installments to make this point.
SLOB for More Than Physical IOPS
I routinely speak about how to use SLOB to study host characteristics such as NUMA and processor threading (e.g., Simultaneous Multithreading on modern Intel Xeons). This sort of testing is possible when the sum of all SLOB schemas fit into the SGA buffer pool. When testing in this fashion, the key performance indicators (KPI) are LIOPS (Logical I/O per second) and SQL Executions per second.
This blog post is aimed at suggesting yet another manner of platform testing with SLOB–specifically concurrent bulk data loading.
The SLOB data loader (~SLOB/setup.sh) offers the ability to test non-parallel, concurrent table loading, index creation and CBO statistics collection.
In this blog post I’d like to share a “SLOB data loading recipe kit” for those who wish to test high performance SLOB data loading. The contents of the recipe will be listed below. First, I’d like to share a platform measurement I took using the data loading recipe. The host was a 2s20c40t E5-2600v2 server with 4 active 8GFC paths to an XtremIO array.
The tar archive kit I’ll refer to below has the full slob.conf in it, but for now I’ll just use a screen shot. Using this slob.conf and loading 512 SLOB schema users generates 1TB of data in the IOPS tablespace. Please note the attention I’ve drawn to the slob.conf parameters SCALE and LOAD_PARALLEL_DEGREE. The size of the aggregate of SLOB data is a product of SCALE and the number of schemas being loaded. I drew attention to LOAD_PARALLEL_DEGREE because that is the key setting in increasing the concurrency level during data loading. Most SLOB users are quite likely not accustomed to pushing concurrency up to that level. I hope this blog post makes doing so seem more worthwhile in certain cases.

The following is a screenshot of the output from the SLOB 2.2 data loader. The screenshot shows that the concurrent data loading portion of the procedure took 1,474 seconds. On the surface that would appear to be a data loading rate of approximately 2.5 TB/h. One thing to remember, however, is that SLOB data is loaded in batches controlled by LOAD_PARALLEL_DEGREE. Each batch loads LOAD_PARALLEL_DEGREE number of tables and then creates a unique indexes and performs CBO statistics gathering. So the overall “data loading” time is really data loading plus these ancillary tasks. To put that another way, it’s true this is a 2.5TB data loading use case but there is more going on than just simple data loading. If this were a pure and simple data loading processing stream then the results would be much higher than 2.5TB/h. I’ll likely blog about that soon.

As the screenshot shows the latest SLOB 2.2 data loader isolates the concurrent loading portion of setup.sh. In this case, the seed table (user1) was loaded in 20 seconds and then the concurrent loading portion completed in 1,474 seconds.
That Sounds Like A Good Amount Of Physical I/O But What’s That Look Like?
To help you visualize the physical I/O load this manner of testing places on a host, please consider the following screenshot. The screenshot shows peaks of vmstat 30-second interval reporting of approximately 2.8GB/s physical read I/O combined with about 435 MB write I/O for an average of about 3.2GB/s. This host has but 4 active 8GFC fibre channel paths to storage so that particular bottleneck is simple to solve by adding another 4 port HBA! Note also how very little host CPU is utilized to generate the 4x8GFC saturating workload. User mode cycles are but 15% and kernel mode utilization was 9%. It’s true that 24% sounds like a lot, however, this is a 2s20c40t host and therefore 24% accounts for only 9.6 processor threads–or 5 cores worth of bandwidth. There may be some readers who were not aware that 5 “paltry” Ivy Bridge Xeon cores are capable of driving this much data loading!
NOTE: The SLOB method is centered on the sparse blocks. Naturally, fewer CPU cycles are required for loading data into sparse blocks.
Please note, the following vmstat shows peaks and valleys. I need to remind you that SLOB data loading consists of concurrent processing of not only data loading (Insert as Select) but also a unique index creation and CBO statistics gathering. As one would expect I/O will wane as the loading process shifts from the bulk data load to the index creation phase and then back again.

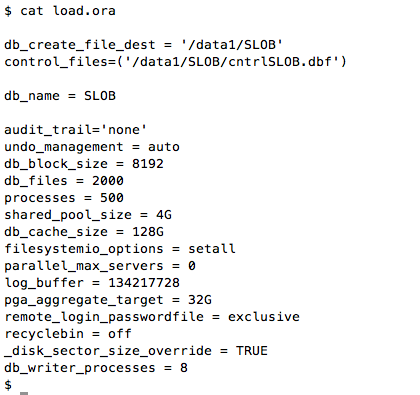
Finally, the following screenshot shows the very minimalist init.ora settings I used during this testing.
The Recipe Kit
The recipe kit can be found in the following downloadable tar archive. The kit contains the necessary files one would need to reproduce this SLOB data loading time so long as the platform has sufficient performance attributes. The tar archive also has all output generated by setup.sh as the following screenshot shows:

The SLOB 2.2 data loading recipe kit can be downloaded here (click here). Please note, the screenshot immediately above shows the md5 checksum for the tar archive.
Summary
This post shows how one can tune the SLOB 2.2 data loading tool (setup.sh) to load 1 terabyte of SLOB data in well under 25 minutes. I hope this is helpful information and that, perhaps, it will encourage SLOB users to consider using SLOB for more than just physical IOPS testing.



1 Response to “SLOB Data Loading Case Studies – Part II. SLOB 2.2 For High-Bandwidth Data Loading.”