This blog post has been necessary for quite some time but I just now finally got around to posting it. What I’m going to blog about is a common problem I run into in my dealings with Oracle Database Administrators (DBAs). It’s about IOPS data in Automatic Workload Repository (AWR) reports. Please don’t roll your eyes. Not everyone gets this right. I’ll explain…
I cannot count how many times I’ve had DBAs cite some IOPS number from their workload only to later receive an AWR report from them that shows a mere fraction of what they think their IOPS load is. This happens very frequently!
I’m going to explain why this happens and then show how to stop getting confused about the data.
At issue is the AWR report generated by awrgrpt.sql which is a RAC AWR report. DBAs will run this script, generate a report, open it and scroll down to the System Statistics – Per Second section so they can see “Physical Reads/s”. That’s where the problem starts. That doesn’t mean it’s the DBAs fault, per se. Instead, I blame Oracle for using the column heading “Physical Reads/s” because, well, that’s 100% erroneous.
A Case Study
To make this topic easier to understand, I set up a small SLOB test. The SLOB driver script (runit.sh) produces both the RAC (awrgrpt.sql) and non-RAC (awrrpti) AWR reports. First, I’ll describe why SLOB can make this so easy to understand.
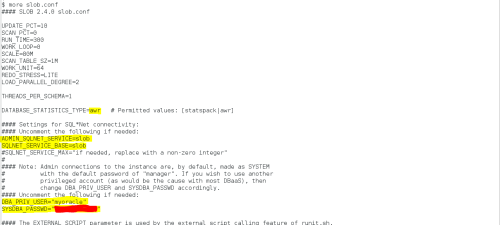
The following screenshot shows the slob.conf I used. You’ll notice that I loaded a “scan table” of 1GB for each schema. Not shown is the fact that I loaded 64 schemas.
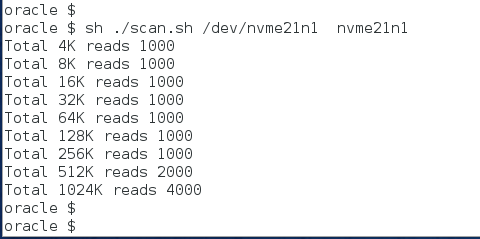
For this type of testing I used the SLOB “batch” approach as opposed to a fixed-time test. As Figure 1 shows, I set the WORK_LOOP parameter to 10, which establishes that each of the sessions will perform 10 iterations of the “work loop”–a “batch” of work as it were. To make the SLOB test perform nothing but table scans, I set SCAN_PCT to 100 and UPDATE_PCT to 0.

Figure 1: SLOB Configuration File.
The runit.sh script produces both the RAC and non-RAC flavor of AWR report in compressed HTML format. The files are called awr.html.gz awr_rac.html.gz.
The RAC report differs from the non-RAC AWR report in both obvious and nonobvious ways. Obviously, a RAC report includes per-instance statistics for multiple instances, however, the RAC report also includes categories of statistics not seen in the non-RAC report. It is, in fact, one of the classes of statistics–only present in the RAC AWR report–that causes the confusion for so many DBAs.
Understandable Confusion – Words Matter!
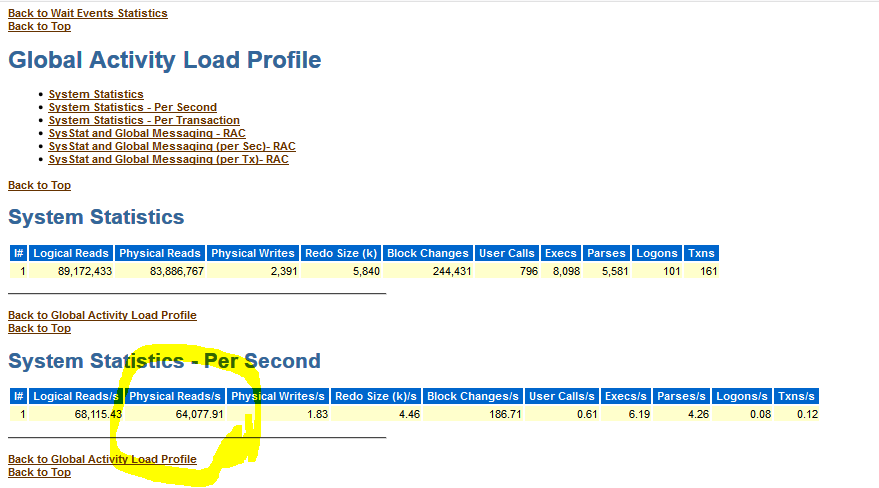
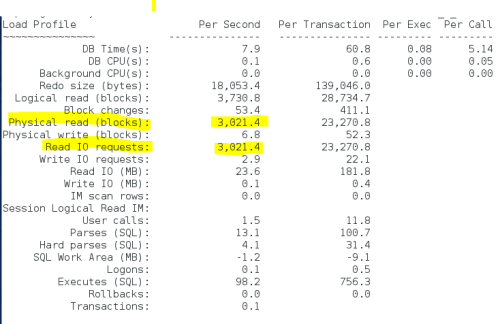
Figure 2 shows a snippet of the RAC AWR report generated during the SLOB test. The screenshot shows the crux of the matter. To check on IOPS, many DBAs open the RAC AWR report and scroll to the Global Activity Load Profile where the per-second system statistics section supposedly reports physical reads per second. I’m not even going to spend a moment of your time to split the hairs that need splitting in this situation because the rest of the RAC report clarifies the erroneous column heading.
Simply put, the simple explanation for this simple problem is that Oracle simply chose an incorrect–if not simply over-simplified–column heading in this section of the RAC AWR report.
Logical and Physical I/O
Figure 2 shows the erroneous column heading. In this section of the RAC AWR report, both logical I/O and physical I/O are reported. In this context, all logical I/O in Oracle are single-block operations. What’s being reported in this section is that there were 68,115 logical reads per second of which 64,077 required a fetch from storage as the result of a cache miss. If Oracle suffers a miss on a logical I/O (which is an operation to find a cached, single block in SGA block buffer pool), the resultant action is to get that block from storage. Whether the missed block is “picked up” in a multi-block read or a single-block read is not germane in this section of the report. That said, I still think the column heading is very poorly worded. It should be “Blocks Read/s”.

Figure 2: RAC AWR Report. Global Activity Load Profile.
What are IOPS? Operations! IOPS are Operations!
That heading made me think of Charlton Heston swinging off the back of a garbage truck yelling, “It’s Operations, IOPS is Operations”. Some may get the Soylent Green reference. Enough of my feeble attempt at humor.
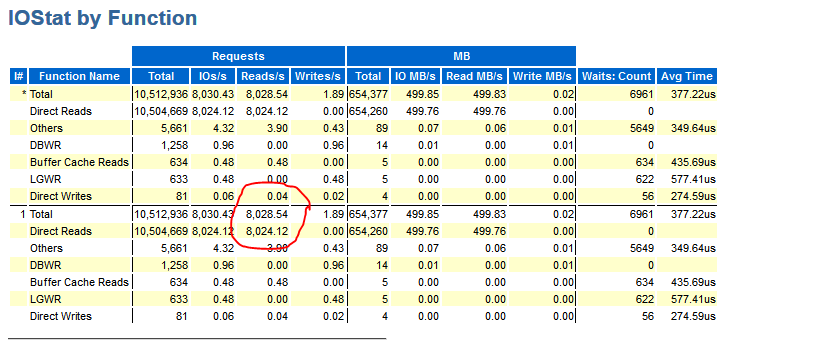
The acronym IOPS stands for I/O operations per second. The word operations is critical. An I/O operation in, Oracle database, is a system call to transfer data to or from storage. Further down in the RAC AWR is the IOStat by Function section which uses a term that maps precisely to IOPS–requests. Another good term for an I/O operation is a request–a request of the operating system to transfer data–be it a read or a write. An operation–or a request–to transfer data comes in widely varying shapes and sizes. Figure 3 shows that the SLOB test described above actually performed approximately 8,000 requests–or, operations–per second from storage in the read path.
I’ll reiterate that. This workload performed 8,000 IOPS.
That’s a far cry less than suggested in Figure 2.

Figure 3: RAC AWR Report. IOStat by Function.
Further down in the RAC AWR report, is the Global Activity Statistics section. This section appears in both the RAC and non-RAC reports. Figure 4 shows a snippet of the Global Activity Statistics section from the RAC report generated during the SLOB. Here again we see the unfortunate misnomer of the statistic that actually represents the number of blocks retrieved from storage. Figure 4 shows the same 64,000 “physical reads” seen in Figure 2, however, there are adjacent statistics in the report to help make information out of this data. Figure 4 ties it all together. The workload performed some 8,000 read requests from storage. What was read from storage? Well, 64,000 blocks per second where physically read from storage.
Let’s Go Shopping
I have a grocery-shopping analogy in mind. Think of a requests as each time you transfer an item from the shelf to your cart. Some items are simple, single items like a bottle of water and others are multiple items in a package such as a pallet of bottled water. In this analogy, the pallet of bottled water is a multi-block read and the single bottle is, unsurprisingly, a single-block read. The physical reads statistic is the total number of water bottles–not items–placed into the cart. The number of item’s placed in the cart per second was 8,000 by way of plopping something into the cart 8,000 times per second. I hope the cart is huge.

Figure 4: Global Activity Statistics. RAC AWR Report.
As mentioned earlier in this post, the RAC AWR report is really just a multi-instance report. In this case I generated a multi-instance report that happened to capture a workload from a single-instance. That being the case, I can also read the non-RAC AWR report because it too covers the entire workload. If everyone, always, read the non-RAC AWR report there would never be any confusion about the difference between reads and payload (read requests and blocks read)–at least not since Oracle Database 11.2.0.4.
Starting in the final patchset release of 11g (11.2.0.4), the Load Profile section (which does not appear in the RAC AWR report) clearly spells out the situation with the “Physical read” misnomer. Figure 5 shows the Load Profile in the non-RAC report generated by the SLOB test. Here we can see that late in 11g there were critical, parenthesized, words added to the output. What was once reported only as “Physical reads” became “Physical read(blocks)” and the word requests was added to help DBAs determine both IOPS (requests per second are IOPS) and the payload, Again, we can clearly see that the test had an I/O workload that consisted of 8,000 requests per second for 64,000 blocks per second for a read throughput of 500MB/s.

Figure 5: Non-RAC AWR. Load Profile Section. Simple and Understandable I/O Statistics.
Wrapping It All Up
I hope a few readers make it to this point in the post because there is a spoiler alert. Below you’ll find links to the actual AWR reports generated by the SLOB test. Before you read them I feel compelled to throw this spoiler alert out there:
I set db_file_multiblock_read_count to 8 with the default Oracle Database block size.
That means processes were issuing 64KB read requests to the operating system.
With that spoiler alert I’m sure most readers are seeing a light come on. The test consists of 64 sessions performing 64KB reads. The reports tell us there are 8,000 requests per second (IOPS) and 64,077 blocks read per second for a read throughput of 500MB/s.
500MB / 8,000 == 64KB.
Links to the AWR reports:
https://github.com/therealkevinc/AWRS/blob/master/awr.html
https://github.com/therealkevinc/AWRS/blob/master/awr_rac.html
Click the following link and githup will give you a ZIPed copy of these AWR reports: https://github.com/therealkevinc/AWRS/archive/master.zip






















Recent Comments